
Your cron job exited zero. Fine. Where is the artifact?
That is the question I want on every scheduled job review now. Not “did the process run?” Not “did the dashboard stay green?” Not “did the log avoid a stack trace?” A scheduled job is healthy only when the expected artifact exists, is fresh, and passes a domain check. Anything weaker is process theater.
I learned this the boring way: daily automations that returned success while producing stale files, empty drafts, partial JSON, or a social post with no live URL. The shell was satisfied. The work was not done. Classic cron monitoring catches missed schedules and non-zero exits. It does not know whether your export has rows, whether your blog post reached content/posts/, whether your agent wrote the report, or whether a downstream consumer can use the output.
This is a hands-on tutorial and deep-dive for fixing that gap. It works for backups, analytics pulls, AI agent jobs, static-site publishing, and any task where the real deliverable is an artifact. The pattern is deliberately small: define the artifact contract, wrap the producer, verify the artifact, then ping success. You do not need a new platform to start. You need one scheduled job, one verifier, and the discipline to make the success signal come after the result is inspected.
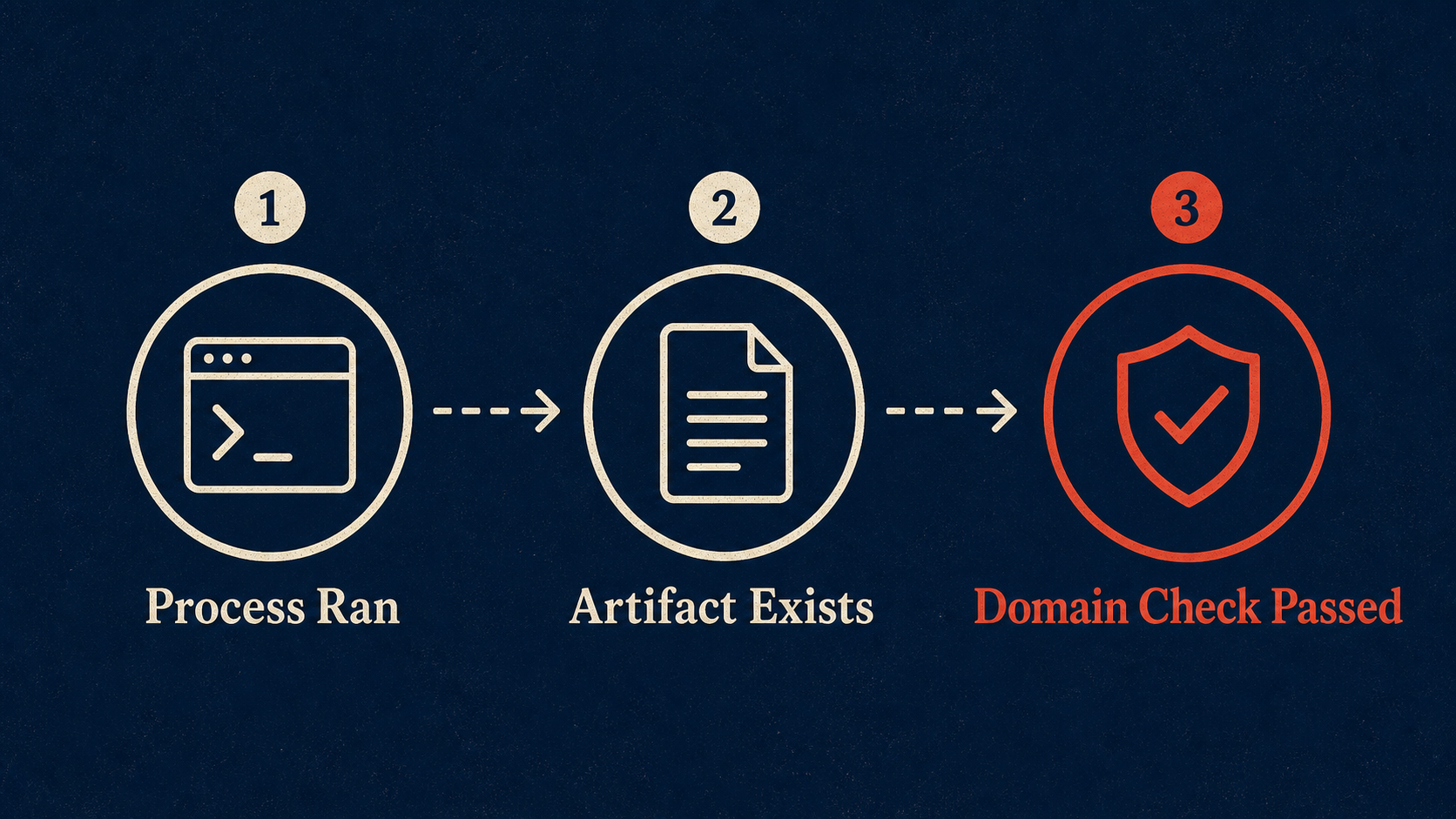
Process health and artifact health are different signals
Most cron monitoring starts with a heartbeat. A job sends a ping when it completes; if the ping does not arrive on time, the monitor alerts. Healthchecks.io documents this pattern directly: the cron job sends an HTTP request every time it completes, and the service notifies you when the ping does not arrive at the expected time. [Source: https://healthchecks.io/docs/monitoring_cron_jobs/]
That is useful. Keep it. It catches jobs that never ran, servers that died, schedules that drifted, and scripts that crashed before the final ping.
But heartbeat monitoring answers one question: did the job report completion? It does not answer the more expensive question: did the job produce useful work?
Cronitor’s public examples show the same completion-ping pattern, with richer metadata such as duration and counts attached to a completion request. [Source: https://cronitor.io/cron-job-monitoring] That metadata is the hint. A serious job should not just say “complete.” It should say “complete, and here is the artifact I produced, here is its size, here is its age, here is the record count, here is the URL that returned HTTP 200.”
The distinction matters because many failures are not crashes. A web-alert guide phrases the problem plainly: a job can succeed with exit code 0 while producing wrong results, such as processing 0 records instead of 10,000. [Source: https://web-alert.io/blog/cron-job-monitoring-background-tasks]
For AI agent jobs, this gets worse. Bob Renze documented an AgentChat silent failure where a health check cron ran 180 times across six hours and logged warnings, but the human was not notified. [Source: https://dev.to/bobrenze/ai-agent-silent-failures-what-6-hours-of-undetected-downtime-taught-me-about-monitoring-3ja8] That number belongs to Renze’s system, not mine. The lesson generalizes: if the job can report activity while failing to produce output, the artifact is the only honest witness.
Here is the simple model I use:
| Layer | Question | Example check | Failure it catches |
|---|---|---|---|
| Process | Did the command exit cleanly? | exit code, timeout, final ping | crashes, missed schedules |
| Artifact | Did the deliverable exist? | file exists, non-zero size, mtime | empty output, wrong path, stale file |
| Domain | Is the deliverable useful? | JSON field, row count, HTTP 200, word count | partial work, no-op success, broken downstream |
The first layer is necessary. The second and third layers are where most silent failures die.
This also changes alert quality. A page that says “cron missed expected ping” is useful, but it still leaves the responder asking what state the job left behind. A page that says “daily-social.json is 91 bytes, missing platforms, and contains empty result” points straight at the failure. The responder knows whether to rerun collection, inspect credentials, or backfill a downstream table. Artifact checks turn monitoring from a binary alive/dead signal into a short diagnosis attached to the artifact that users actually depend on.
Start every scheduled job by naming the artifact
Before writing a verifier, write one sentence:
This job is successful when
[artifact]exists, is newer than[freshness window], and passes[domain check].
That sentence forces decisions that logs hide.
For a database backup, the artifact is a compressed dump file. It must be larger than a minimum size, newer than the schedule window, and restorable enough that pg_restore --list can read it.
For a static-site blog job, the artifact is not /tmp/blog-draft.md. A draft is an intermediate. The real artifact is the published post under content/posts/, the generated page under public/posts/<slug>/, the pushed commit, and the live URL returning HTTP 200.
For an analytics job, the artifact is not “script finished.” It is a JSON snapshot containing a date, platform names, and numeric metrics. An empty array may be valid for some systems, but if your daily social report normally contains platform metrics, an empty array is a failure until proven otherwise.
For an AI agent cron, the artifact is often a Markdown report, a queue state transition, a database row, a pull request, or a scheduled Buffer post ID. The verifier should inspect that object, not the agent’s self-report.

A useful artifact contract has four fields:
| Field | Meaning | Bad default |
|---|---|---|
| Path or handle | Where the result must appear | relying on stdout only |
| Freshness window | How new it must be | accepting yesterday’s file |
| Minimum substance | Size, rows, words, records, IDs | accepting a zero-byte file |
| Domain assertion | The result is actually usable | checking only file existence |
The point is not bureaucracy. The point is making success machine-checkable.
Be careful with artifacts that represent intentional emptiness. Some jobs legitimately produce zero records: no failed payments today, no abuse reports this hour, no new leads overnight. Do not let that case weaken the verifier into accepting any empty output. Encode the idle state explicitly. A JSON artifact can say {"status":"idle","reason":"no_new_records","checked_at":"..."}. A Markdown report can contain a required ## No incidents section. The difference between “nothing happened” and “the job failed to look” must appear in the artifact, not in a human’s memory of how the system usually behaves.
Wrap the job so verification runs on every exit path
The easiest shell pattern is an EXIT trap. The job does its work. The trap verifies the artifact. If the job exits zero but the artifact fails validation, the wrapper exits non-zero.
| |
This wrapper is intentionally plain. set -euo pipefail catches common shell mistakes. The verifier is separate Python because artifact checks grow quickly. The heartbeat happens after validation, not before it.
Healthchecks.io shows the common cron pattern where a successful script is followed by curl to a ping URL. [Source: https://healthchecks.io/docs/monitoring_cron_jobs/] Move that ping behind your artifact verifier. A ping before verification says “the process ended.” A ping after verification says “the deliverable survived inspection.”
There is one subtle choice in the wrapper: if the original job failed with a non-zero status and the artifact still verifies, the wrapper preserves the original status. That is conservative. You can change it for jobs where artifact validity is the only success signal, but do it deliberately.
Use a verifier that checks existence, freshness, size, and content
Here is a small Python verifier I keep around. It is boring on purpose. It checks that a file exists, is recent enough, is large enough, avoids known failure markers, and optionally contains required JSON fields.
| |
Run it locally before wiring it to cron:
| |
Do not make the verifier clever too early. Clever verifiers become another silent failure surface. Start with four boring checks. Add domain checks only when a real incident proves you need them.
Put domain checks close to the domain
A file can exist and still be wrong. That is where domain checks earn their keep.
For a blog publish job, I would check all of these before reporting success:
| |
For an analytics job, the domain check is different. You care about schema and numbers:
| |
For a queue worker, the artifact may be a database transition: pending to done, done_at within the run window, and a non-empty result payload. For a crawler, it may be row count plus dedupe ratio. For an AI agent, it may be a file, a task ID, a commit SHA, or a Buffer post ID.

The domain check should be owned by the team that owns the domain. Operations can tell you whether the process ran. Only the domain can tell you whether the work matters.
Wire the verifier into cron and CI
Here is a crontab entry that treats the wrapper as the only scheduled command:
| |
And here is a GitHub Actions version for a scheduled static-site check:
| |
The ordering is the whole point. Run job. Verify artifact. Ping monitor. Report success.
If you ping before verification, the monitor becomes a diary of attempts. If you ping after verification, it becomes a signal of completed work.
What you should do Monday morning
Pick three scheduled jobs. Do not start with the whole fleet. Choose one that writes a file, one that calls an API, and one that publishes something visible.
For each job, write the artifact contract sentence:
- What exact artifact proves success?
- How fresh must it be?
- What minimum size, row count, word count, or ID must exist?
- What domain assertion proves it is usable?
Then add the smallest verifier that catches the failure you already know is possible. A backup verifier does not need a full restore on day one; it can start with non-zero size and pg_restore --list. A blog verifier does not need browser automation on day one; it can start with frontmatter, word count, generated HTML, and HTTP 200. An agent verifier does not need full semantic grading; it can start with non-empty output, absence of failure markers, and a task state transition.
After that, move your success ping behind the verifier. This is the step that changes behavior. The monitoring service should only receive a success signal after the artifact passes. Send failure metadata if your monitor supports it. Cronitor documents completion pings with optional metadata such as duration and count; use that style to send artifact size, row count, or URL status when available. [Source: https://cronitor.io/cron-job-monitoring]
Finally, write down the first false positive. You will get one. In one environment, the minimum byte threshold is too high. On a quiet holiday, a legitimate report produces zero rows. A long-running report needs a wider freshness window. Tune from real misses, not from imagination.
One more practical move: keep the verifier output stable. Print one success line and one failure prefix. ARTIFACT_CHECK_OK and ARTIFACT_CHECK_FAIL are boring strings, which is exactly why they work. Your log search, alert rule, and postmortem notes can key on them without parsing a paragraph of agent prose. If the job uses an LLM, this matters even more. The agent can write fluent explanations all day; the verifier should write a small deterministic sentence that another program can trust.
Also separate retry from verification. Retrying a failed API call is fine. Retrying a failed artifact check can hide damage if the second run overwrites the evidence. When a verifier fails, preserve the bad artifact with a timestamped suffix before the next attempt. A broken JSON file is more useful than a clean log that says the retry eventually worked. Production debugging starts with the first bad artifact, not the final green run.
The real rule
Cron is allowed to say “I ran.” It is not allowed to say “I succeeded” by itself.
For scheduled work, success lives in the artifact. The file exists. The timestamp is fresh. The content has substance. The domain check passes. The downstream URL opens. The queue row moved. The report contains data.
That is the line I use now: no artifact, no success.
Further reading
- Healthchecks.io: monitoring cron jobs with completion pings — https://healthchecks.io/docs/monitoring_cron_jobs/
- Cronitor: cron job monitoring and completion metadata — https://cronitor.io/cron-job-monitoring
- Bob Renze: AI agent silent failures and the six-hour AgentChat incident — https://dev.to/bobrenze/ai-agent-silent-failures-what-6-hours-of-undetected-downtime-taught-me-about-monitoring-3ja8