
A coding agent with a very large context window can still make the wrong change in the wrong file.
That sounds harsh until you watch the failure happen. The agent reads half the repository, quotes three irrelevant modules back at you, edits the visible function, and misses the caller that actually owns the invariant. The problem was never that the window was too small. The problem was that the agent had no map.
The next useful jump in AI coding workflows is not another argument about context size. It is structure: compiler-backed code graphs, artifact checks, alert rules in Git, and handoffs that force the agent to prove what changed. Bigger context helps when the missing fact is a nearby file. It does not fix keyword-driven wandering, broken retrieval, or a workflow that treats a successful process as a successful deliverable.
This is the production line I want: the agent asks the code graph before it opens ten files, writes a patch against a small set of structural facts, runs checks that produce inspectable artifacts, and ships alert changes as code when behavior changes. Tokens are still useful. They are not the control plane.
1. Context size is a budget, not an architecture
Large context windows are valuable. They let an agent keep more source, logs, docs, and previous reasoning in one pass. The trap is treating that budget as a substitute for retrieval discipline.
Repository work is not a document summarization problem. A bug fix often depends on call chains, type boundaries, re-export paths, generated clients, test fixtures, and operational assumptions that live outside the file with the red line. If the agent gets those relationships wrong, giving it more files simply gives it more ways to sound confident while being wrong.
The ABCoder TypeScript indexing paper states the problem clearly: code agents depend on the quality of context retrieval, and poor retrieval leads to incomplete or misleading input even when the model itself has enough reasoning ability [Source: https://arxiv.org/html/2604.18413v1]. The paper contrasts command-line exploration, similarity retrieval, and graph-based indexing. Grep and find are easy to deploy, but keyword search misses relevant code with different names and returns irrelevant code with the same names. Similarity retrieval helps with natural language matching, but it does not naturally preserve call chains or type dependencies. Graph-based indexing keeps the relationships that matter.
That is the line between “more context” and “better context.” Bigger windows increase the amount of material the model can see. Graphs improve the shape of what the model sees.
Here is the operational distinction I use:
| Question | More context answer | Structured context answer |
|---|---|---|
| Where is this symbol used? | Search text and open many files | Ask a reference edge |
| What breaks if I change this type? | Read callers manually | Traverse dependency and implementation edges |
| Which file owns the invariant? | Guess from filenames | Inspect caller/callee and test links |
| Did the job succeed? | Process exited zero | Artifact exists, is fresh, and passes assertions |
| Did the alert ship? | Dashboard looks updated | Rule lives in Git, CI passed, deploy artifact exists |
A production AI workflow needs the right side of that table.
2. The compiler already has the map
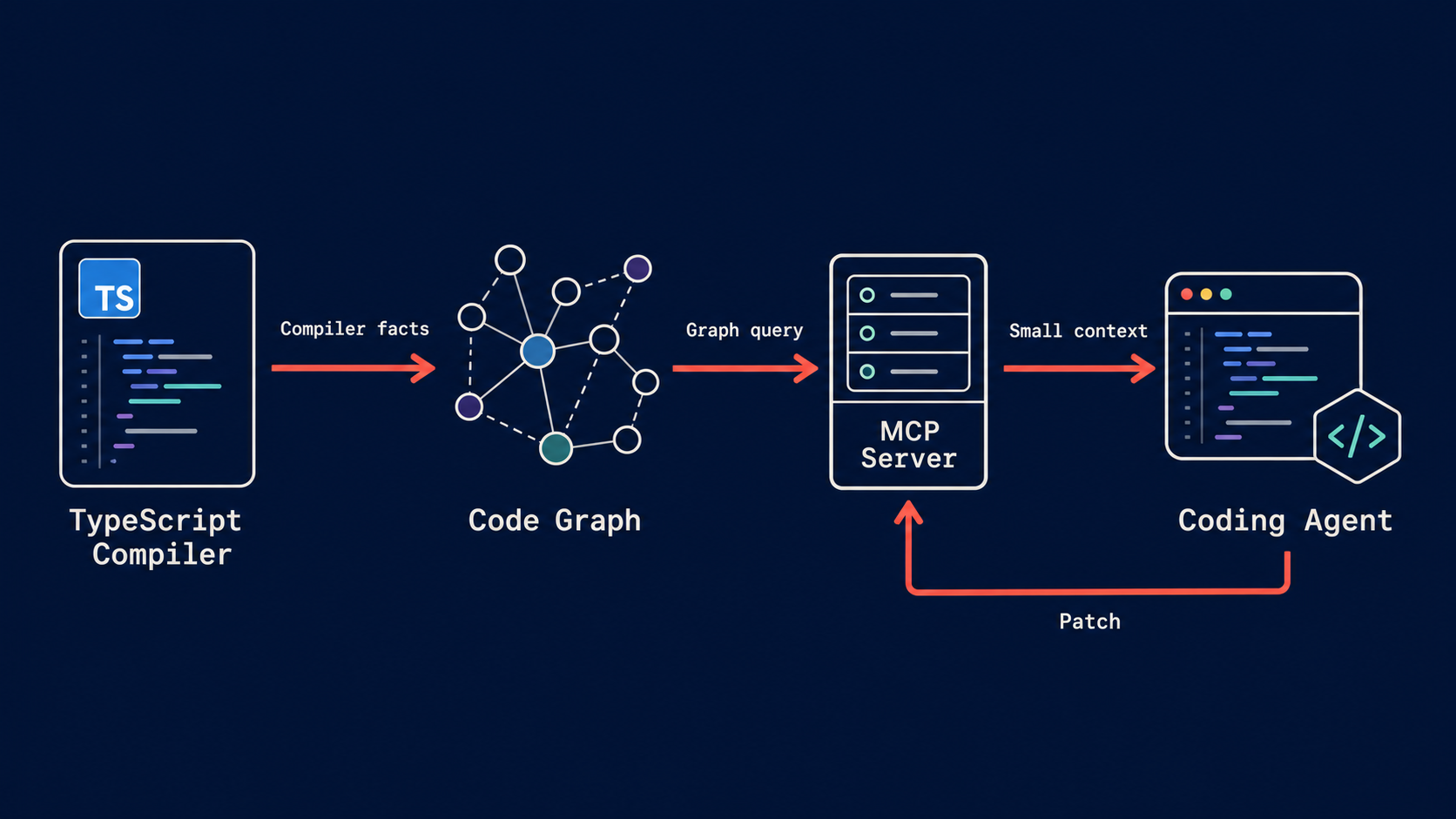
The interesting part of the new TypeScript graph work is not that it uses MCP. MCP is the delivery mechanism. The point is that the TypeScript compiler already understands source files, imports, aliases, re-exports, symbols, type relationships, and diagnostics.
@ttsc/graph exposes that structure to coding agents over MCP. Its README describes a graph of a TypeScript codebase: what calls what, what depends on what, and where each piece lives. It is drawn by the real TypeScript compiler, with claims anchored to file and line locations [Source: https://github.com/samchon/ttsc/tree/master/packages/graph]. The package describes one MCP tool, inspect_typescript_graph, with operations such as tour, entrypoints, lookup, trace, details, overview, and escape. It returns names, edges, signatures, and spans rather than dumping source bodies, keeping responses flatter as repositories grow [Source: https://github.com/samchon/ttsc/tree/master/packages/graph].
The setup is intentionally boring:
| |
| |
The current package notes that it reads the graph from the program ttsc type-checked, and that ttsc runs on the TypeScript-Go / TypeScript v7 runtime with typescript@rc, not stable TypeScript v6.x yet [Source: https://github.com/samchon/ttsc/tree/master/packages/graph]. That matters. This is not a universal default for every production repo today. It is a concrete example of the direction: compiler truth as agent context.
ABCoder reaches the same direction from the indexing side. Its TypeScript parser uses the TypeScript Compiler API directly so the parser can load the whole project into one in-process compiler instance and access AST, semantic information, and module resolution without per-symbol JSON-RPC calls to a language server [Source: https://arxiv.org/html/2604.18413v1]. The paper reports evaluation on three open-source TypeScript projects with up to 1.2 million lines of code and describes a test suite of 10 test suites and 175 test cases, with 174 passing at the time of publication [Source: https://arxiv.org/html/2604.18413v1].
Do not over-read those numbers. They do not prove every graph tool is ready for every team. They prove the shape of the fix: use the compiler’s semantic model instead of forcing the agent to reconstruct a repo through terminal archaeology.
3. A graph beats file soup during real changes
A good graph tool does not replace reading code. It changes the order.
Without a graph, the agent starts with filenames and text matches. It opens the obvious file, follows imports by hand, runs another search, opens a test, forgets the first constraint, and spends tokens deciding what to read next. That is normal for a human exploring a new codebase. It is wasteful for an agent doing a bounded change.
With a graph, the agent can ask structural questions first:
| |
That last bullet matters. The @ttsc/graph README explicitly says the tool has an escape path when the graph is not the right source [Source: https://github.com/samchon/ttsc/tree/master/packages/graph]. A graph should not pretend to answer product intent, runtime data, feature flags, or customer reports. It should answer structure quickly and stop.
Here is a small pattern I would use in an agent instruction file:
| |
This rule is not glamorous. It prevents the common failure where an agent reads a wide folder and still misses the dependency edge that matters.
The same discipline applies outside TypeScript. Tree-sitter graphs, LSP-backed indexes, repo maps, and language-specific analyzers all point in the same direction. The implementation varies by stack. The principle does not: give the agent relationships before raw volume.
4. Artifact checks turn agent work into evidence
A graph helps the agent choose the right edit. It does not prove the work happened.
That proof comes from artifacts. A scheduled agent run, a code-mod job, a migration assistant, or a documentation generator should not report success because the process exited zero. It should report success because the expected output exists, is fresh, has substance, and passes a domain assertion.
I use this contract:
| |
Then the success ping sits behind verification:
| |
This is where context-window thinking falls apart. A giant model context does not create a durable success signal. It does not tell tomorrow’s cron job whether today’s agent actually wrote the report, generated the page, pushed the branch, or shipped the alert. The workflow needs an artifact contract.
This also changes how you debug agents. Instead of asking, “Why did the model say it was done?” you ask, “Which artifact assertion failed?” That is a better question because it points to code, not vibes.

5. Alerts belong in the same repository discipline
When an agent changes behavior, monitoring often changes too. New job, new queue, new external dependency, new data import, new failure mode. If the alert rule is a dashboard click performed after the merge, the workflow has a blind spot.
Detection as Code and Monitoring as Code give the same lesson from another direction. Splunk describes Detection as Code as treating detections like software: versioned, owned, testable, and automated through Git and CI/CD instead of manual UI workflows [Source: https://www.splunk.com/en_us/blog/learn/detection-as-code.html]. The same article lists concrete practices: write rules in YAML or Python, store them in Git, test and deploy them with CI/CD, and validate behavior against known log samples [Source: https://www.splunk.com/en_us/blog/learn/detection-as-code.html].
The SRE Monitoring-as-Code repository describes Jsonnet mixins for SLIs, SLOs, error budgets, Prometheus rules, Grafana dashboards, and runbooks. Engineers commit a monitoring definition file, which triggers packaging of Prometheus rules and Grafana dashboards into the monitoring tools [Source: https://github.com/HO-CTO/sre-monitoring-as-code].
That is the right mental model for AI-assisted development. If an agent adds a background worker, it should also open the alert definition that proves the worker is alive and producing useful artifacts. If it changes the failure mode of a payment job, the detection rule should be reviewed beside the code. If it adds a retry loop, the alert should watch for retry storms, not just crashes.
A minimal alert rule can start as YAML:
| |
And the CI check can be plain:
| |
The important part is not the specific syntax. The important part is reviewability. Alert logic has owners, tests, diffs, and rollback. That is how you stop an agent workflow from becoming a private conversation between a model and a dashboard.
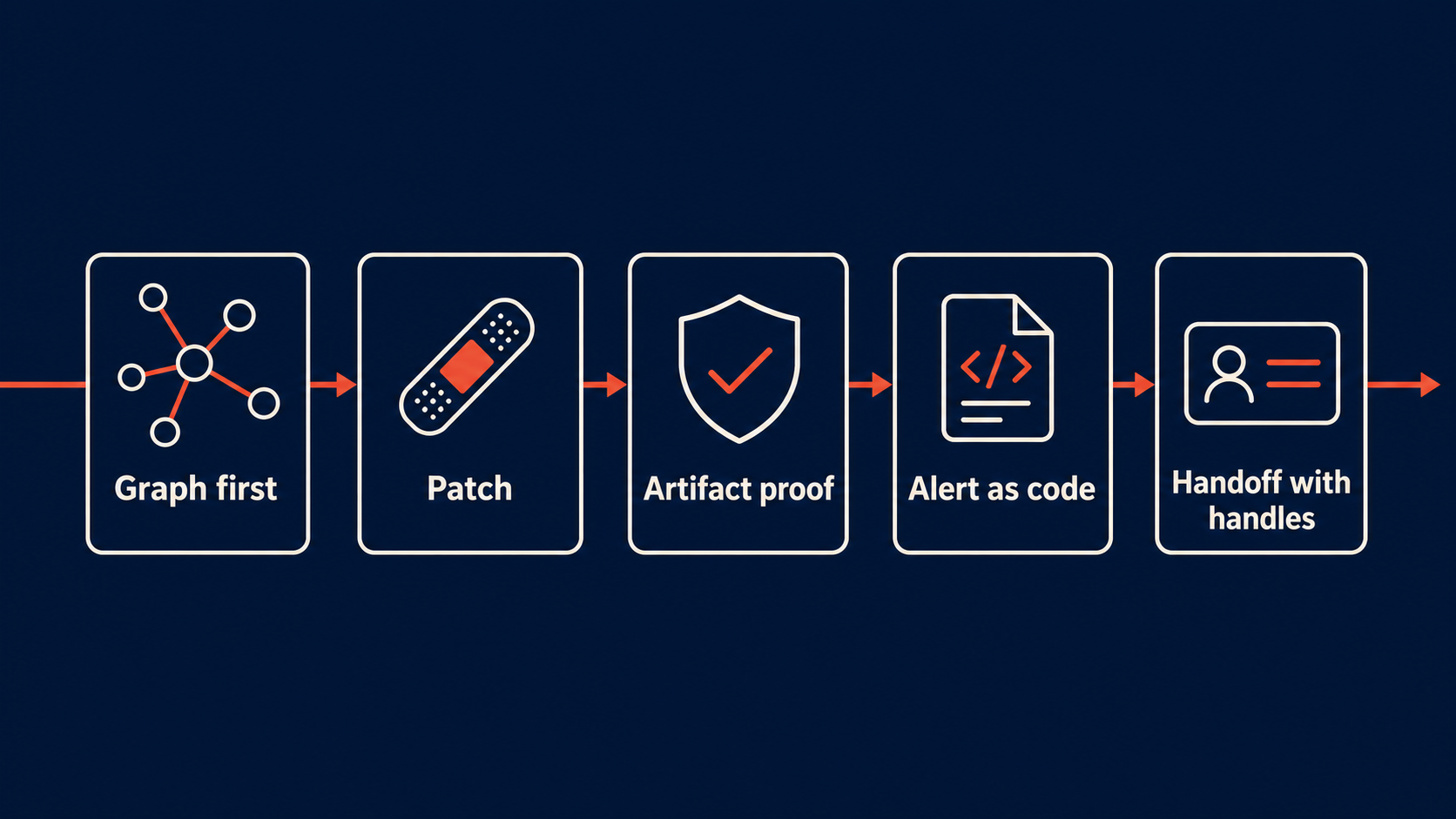
6. The production workflow: graph, patch, artifact, alert
Put the pieces together and the workflow becomes smaller, not larger.
- Graph first. Ask the compiler-backed graph for symbols, callers, callees, entrypoints, diagnostics, and related tests.
- Patch second. Edit only after the structural scope is clear.
- Artifact third. Produce a report, commit, build output, generated page, migration result, or another durable handle.
- Alert fourth. If the behavior runs on a schedule or in production, ship the alert rule as code.
- Handoff last. Summarize the artifact handles, not just the model’s narrative.
This is a different agent contract from “read the repo and fix the bug.” It is closer to a senior engineer’s working agreement:
| |
The contract narrows autonomy in the places that matter. The agent is still free to reason, search, and write code. It is not free to call a task complete without evidence.
This also keeps teams honest about tool maturity. @ttsc/graph currently rides on the TypeScript-Go / TypeScript v7 release-candidate track [Source: https://github.com/samchon/ttsc/tree/master/packages/graph]. ABCoder’s TypeScript parser is a research and open-source indexing path, not a magic production default [Source: https://arxiv.org/html/2604.18413v1]. Detection-as-code practices vary by stack and ownership model. None of this says “install one package and trust the agent.” It says the direction is clear enough to start building the harness.
What you should do Monday morning
Do not start by buying a larger context window. Start with one narrow workflow and make it structured.
Pick a recurring agent task or a common coding-agent failure. Then do this:
- Write the navigation rule. Before editing, the agent must identify callers, callees, entrypoints, related types, and tests. For TypeScript, evaluate a compiler-backed graph path such as
@ttsc/graph. For another stack, choose the strongest structural source you have. - Add an escape rule. The agent must say when the graph is not the right source. Product requirements, runtime logs, and customer reports are not compiler facts.
- Define the artifact contract. Name the file, URL, commit, row, or report that proves useful work happened. Add freshness, substance, and domain assertions.
- Move one alert into Git. Pick the alert most closely tied to that workflow. Store it as YAML, Jsonnet, Python, Terraform, or whatever your monitoring stack accepts. Add a CI validation step.
- Change the final response format. Require handles. A good final response says: changed files, commands run, artifacts verified, alert impact, and next risk. A weak final response says: “done.”
The point is not to reject bigger contexts. Use them when they help. The point is to stop treating them as the main plan.
One more practical rule: write down which source of truth answered each question. Compiler graph for structure. Tests for behavior. Logs for runtime evidence. Artifacts for completion. Alert definitions for production coverage. When those sources disagree, stop the agent and make the disagreement explicit. That pause costs less than a confident patch built on mixed evidence. It also teaches the team which part of the harness deserves investment next.
A coding agent needs memory, tools, and tokens. In production, it needs a map more than it needs a larger backpack.
Further reading
@ttsc/graphREADME — TypeScript compiler graph over MCP: https://github.com/samchon/ttsc/tree/master/packages/graph- ABCoder TypeScript repository indexing paper: https://arxiv.org/html/2604.18413v1
- Splunk Detection as Code guide: https://www.splunk.com/en_us/blog/learn/detection-as-code.html