
I ran an autonomous task system for three months before I realized it had a blind spot the size of a barn door. Processes were “healthy.” CPU was fine. Memory was fine. And yet, nothing was getting done.
One subagent silently died. The parent waited three hours for a response that was never coming. When I finally dug in, I found a queue full of stalled tasks — all of them showing green on the dashboard. None of them had produced useful output in hours.
This is the zombie task problem. Your agent pipeline monitors whether the process is running. It never checks whether the process is actually working.
Traditional monitoring catches uptime. It doesn’t catch behavior. AI agents fail subtly — plausible wrong answers, skipped steps, loops that burn tokens without making progress, context errors that compound silently. No error codes. No crash logs. Just a process that looks alive and a task that’s been dead for hours.
Here’s how to fix that.

The Four Zombie Patterns That Will Eat Your Pipeline
After building detection into our system and auditing three months of logs, four patterns accounted for nearly every silent failure we saw.
1. Infinite Wait. A tool call hangs. No timeout fires. The agent sits there waiting for a response that will never arrive. The process is running. The thread is active. Nothing is happening.
2. Compaction Loop. Context compaction runs, and the agent loses critical state. It starts repeating itself — not obviously, but in a slow drift where each cycle produces slightly less useful output than the last. MindStudio documented this as one of six reasoning-layer failure modes, alongside context degradation, specification drift, and sycophantic confirmation.
3. Subagent Black Hole. A child agent dies. The parent waits forever. This was the one that bit me hardest — a subagent crashed on a memory allocation error, and the parent sat there for three hours with no timeout and no fallback.
4. Rate Limit Sleep. The agent hits a rate limit, backs off, and never wakes up. The retry logic has a bug, or the backoff grows beyond the task’s lifetime, or the wake-up condition never triggers.
These patterns are not theoretical. They show up in every production agent system that runs long enough without behavioral monitoring.
Takeaway: If your monitoring only checks “is the process running,” you’re not monitoring. You’re guessing.
Wall-Clock Timeouts: The Hard Floor
The first and most important fix is simple: every task gets a maximum duration. Not a suggestion. A hard wall-clock timeout that kills the task and triggers recovery.
| |
The key insight: timeouts are not about punishing slow tasks. They’re about bounding the cost of failure. Braintrust traced one production loop that cost 274 LLM calls, 91,547 tokens, and $1.38 before anyone noticed. A wall-clock timeout would have caught it in minutes.
Set your timeouts based on observed p95 completion times, plus a margin. If a task normally takes 5 minutes, give it 15. If it normally takes 30 minutes, give it 60. The goal is to catch the zombie, not to rush the living.
| |
Takeaway: No task should run without a hard time limit. Set it at 2-3x the normal completion time. Enforce it at the process level, not the honor system.
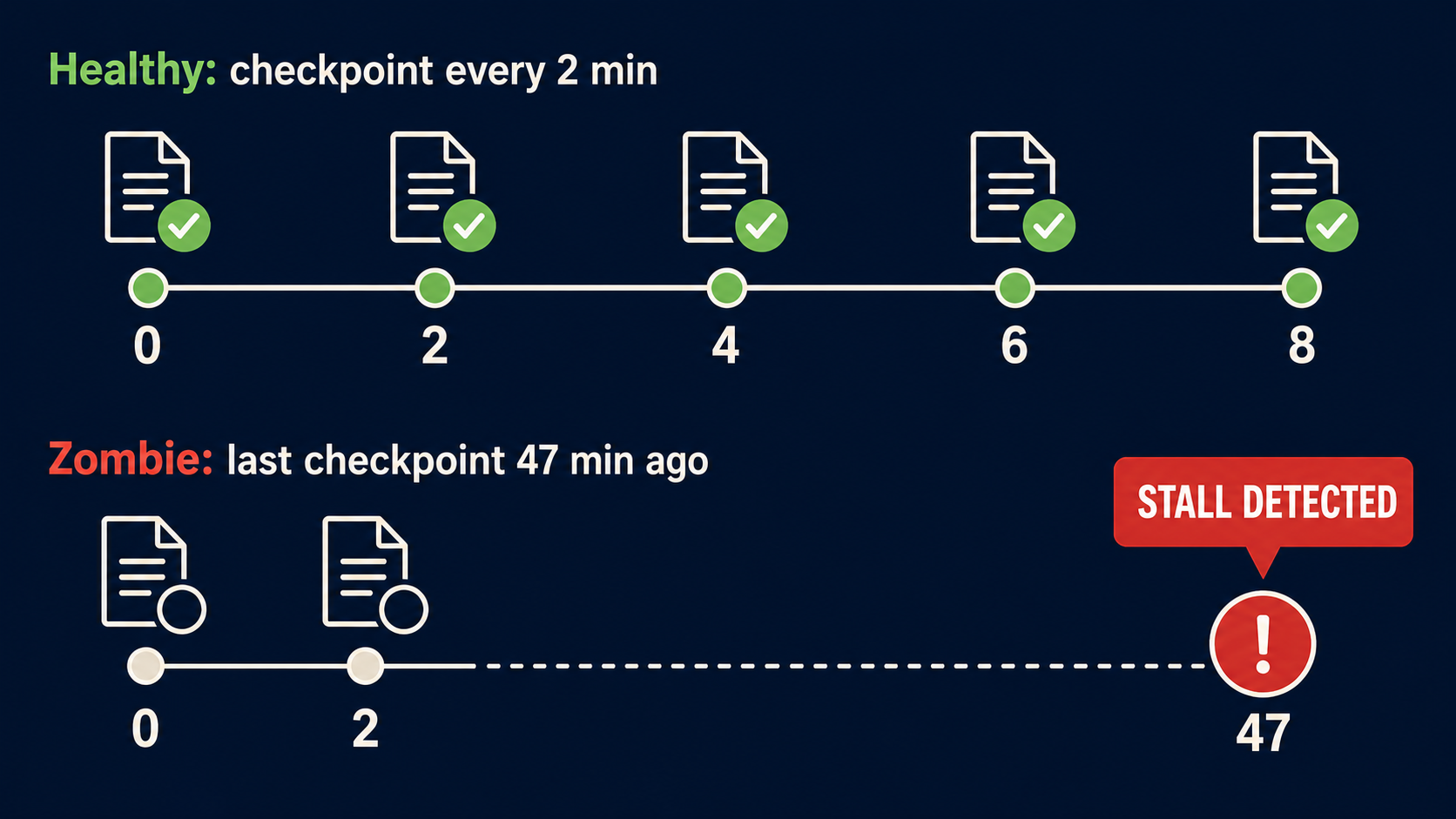
Checkpoint Heartbeats: Proving Progress, Not Just Presence
A timeout tells you when a task has been running too long. But you can do better. You can check whether the task is making progress.
The pattern is checkpoint heartbeats. Every N minutes, the task must write proof that it’s doing useful work. No checkpoint within the window means the task is stalled.
| |
The checkpoint proves progress — files written, records processed, state advanced. A timestamp alone is not enough. Watch the time between checkpoints. If it exceeds your threshold, the task is stalled regardless of what the process metrics say.
Takeaway: A heartbeat that only proves the process is alive is worthless. Your checkpoints must prove progress. Timestamp alone is not enough.
Output Verification: Trust, but Validate
The final layer is output verification. When a task claims it’s done, check the output before you trust it.
This sounds obvious. Most systems don’t do it.
| |
Latitude’s research makes the point clearly: silent failures are invisible. Goal drift, context loss, quality degradation — none of these produce error codes. You need decision-path tracing, not just endpoint monitoring. Output verification is the simplest form of that. Did the task produce what it was supposed to produce? Is the output structurally valid? Is it recent?
UptimeRobot’s research on AI agent failures reinforces this. Agents fail subtly. They produce plausible wrong answers. They skip steps. They loop. Traditional monitoring catches uptime, not behavior. You need to verify the actual artifacts.
Takeaway: Never trust a task’s self-reported completion. Verify the output exists, is non-empty, is recent, and contains the expected structure. This catches more failure modes than any other single check.
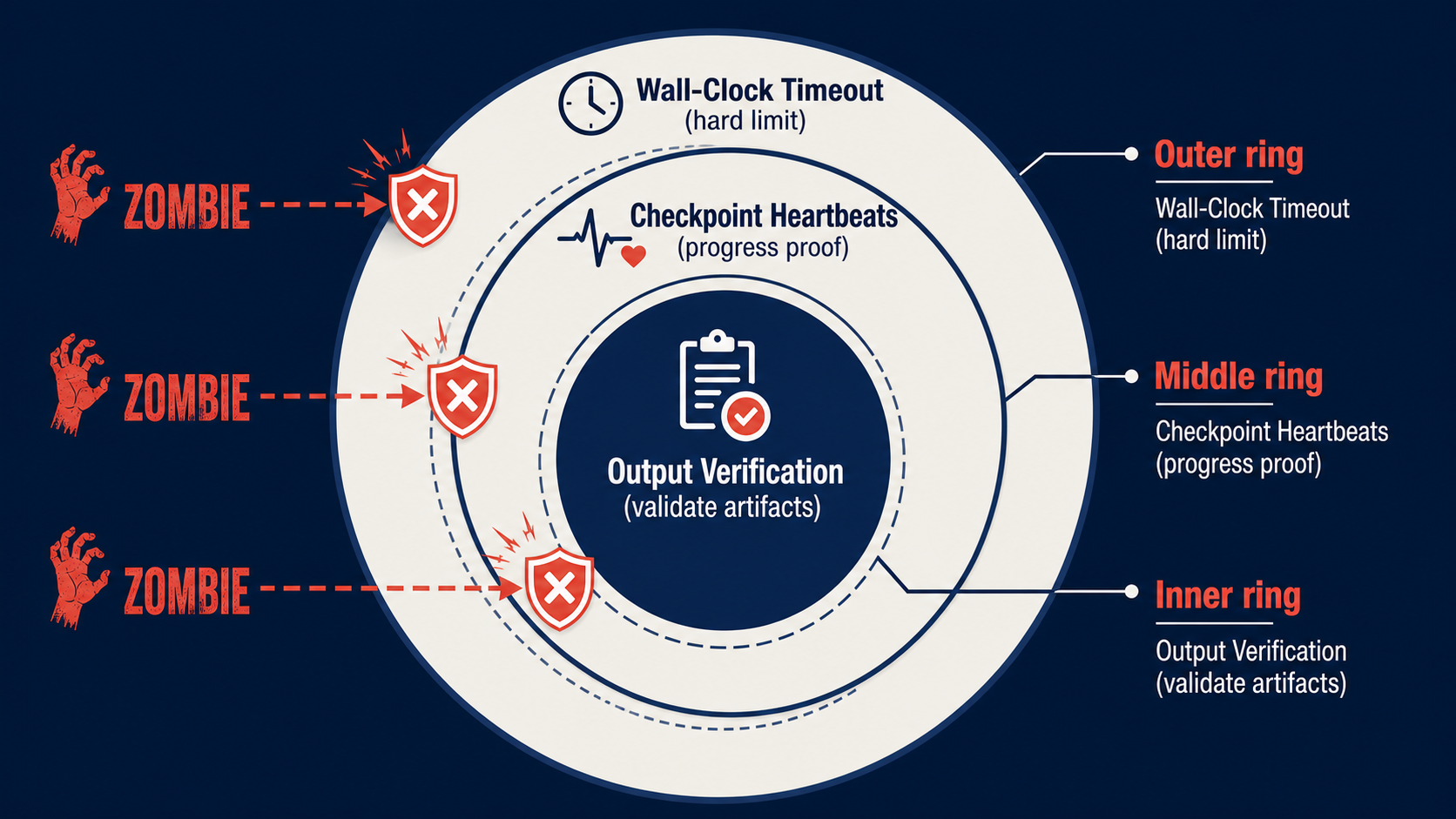
Putting It All Together: A Detection Pipeline
Here’s a minimal orchestrator that combines all three layers:
| |
The entire detection layer — timeouts, heartbeats, output verification — fits in under 150 lines. But it closes the gap that most agent pipelines leave wide open.
What This Costs and What It Saves
Let’s talk numbers.
Before detection: silent failures going unnoticed for hours. Tasks stuck in queues, blocking downstream work. One production loop incident costing 274 LLM calls, 91,547 tokens, and $1.38 — and that was just the one that got noticed.
After detection: silent failures caught within minutes, not hours. Stalled tasks restarted automatically. No more ghost tasks clogging the queue.
The implementation cost is under 150 lines of infrastructure code and a checkpoint directory. The savings are measured in wasted compute, missed SLAs, and the engineering hours spent debugging “mystery” failures that were only mysterious because nobody was looking at the right signals.
MindStudio identified six reasoning-layer failure modes. At least four of them — context degradation, specification drift, tool call failures, and silent failure — produce zombies that traditional monitoring won’t catch. You need behavioral monitoring. Process health is a necessary signal. It is not sufficient.
Takeaway: The detection layer is cheap. The failures it prevents are expensive. Implement wall-clock timeouts first (biggest impact, lowest effort), then checkpoint heartbeats, then output verification. Each layer catches what the previous one misses.
Start Here
If you do one thing after reading this, do this:
Audit your pipeline for missing timeouts. Find every task that has no wall-clock limit. Add one. Set it generous — 3x the normal completion time. Log every timeout. You’ll see more than you expect in the first week.
Add checkpoint heartbeats for long-running tasks. Any task over 5 minutes needs a heartbeat. Make the checkpoint prove progress — files written, records processed, state advanced.
Add output verification for every task that produces artifacts. Files, database writes, API responses — check existence, size, freshness, and structure before marking complete.
Three layers. Under 150 lines of code. Your agents are already failing silently. The only question is whether you’re detecting it.