
Last month, Claude Opus 4.7 hit 1567 Elo on WebDev Arena — the highest any model has ever scored on that benchmark. The same week, GPT-5.5 claimed the Terminal-Bench 2.0 crown at 82.7%. And in Jakarta, where I’ve been shipping software since before npm existed, nobody in my Slack channels cared. The conversation wasn’t about which model is best. It was about which tool lets you use any model — and switch when the numbers stop working in your favor.
This is the real story of AI coding tools in mid-2026. Not which model won a benchmark, but who controls the model choice. The answer increasingly determines whether you ship software or just generate more code that never reaches production.
The Numbers Everyone’s Ignoring
The MIT/NBER working paper from May 2026 contains a finding that should terrify anyone building on top of a single model provider: developers using AI coding tools produced 180% more code, but only 30% more shipped software.
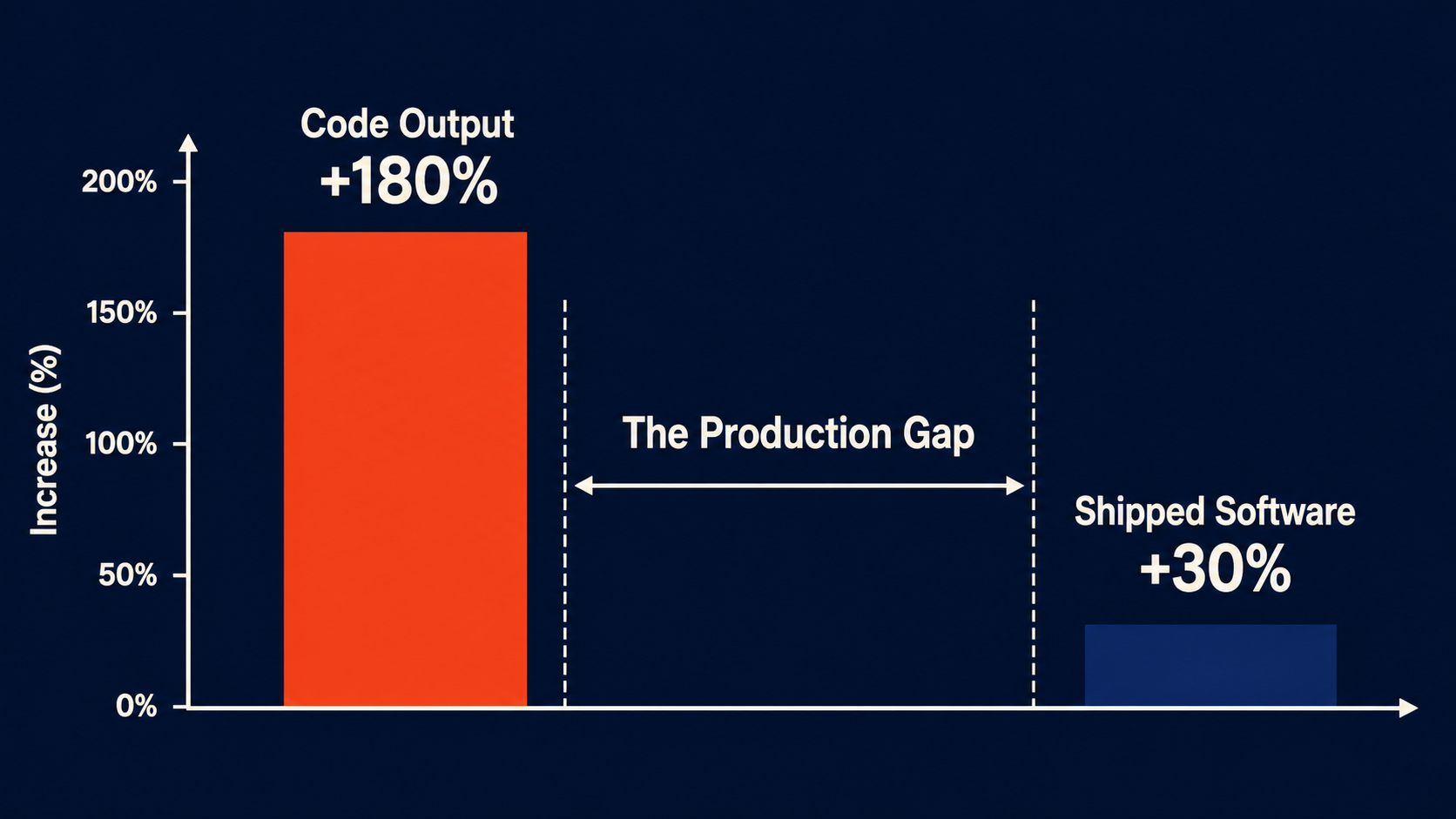
Let those numbers sit. Nearly triple the code. Only a third more actual working software. The gap between those two bars — 150 percentage points of generated code that went nowhere — is what happens when you optimize for output volume instead of output quality. It’s also what happens when your tool is locked into a model that’s great at writing code and terrible at understanding your actual codebase.
This isn’t a knock on any particular model. Claude Opus 4.7 is genuinely excellent at greenfield work. GPT-5.5’s 52.5% reduction in hallucinations is real and significant. But none of those benchmarks measure what happens when you point a model at an 8-year-old monorepo with inconsistent patterns, half-documented APIs, and three generations of technical debt — exactly the kind of codebase most of us work in every day.
The model that scores 1567 on WebDev Arena might be the wrong model for your god-object refactor in a legacy Rails app. The model that runs 35-hour autonomous sessions might be overkill for adding a CRUD endpoint. Portability means you get to make that call.
OpenCode Took #1 by Not Picking a Side
The LogRocket AI Dev Tool Power Rankings for June 2026 tell a story that would have been surprising two years ago: OpenCode is #1, with 160K+ GitHub stars and 7.5 million monthly active developers. Cursor, which held the top spot for most of 2025, dropped to #2.
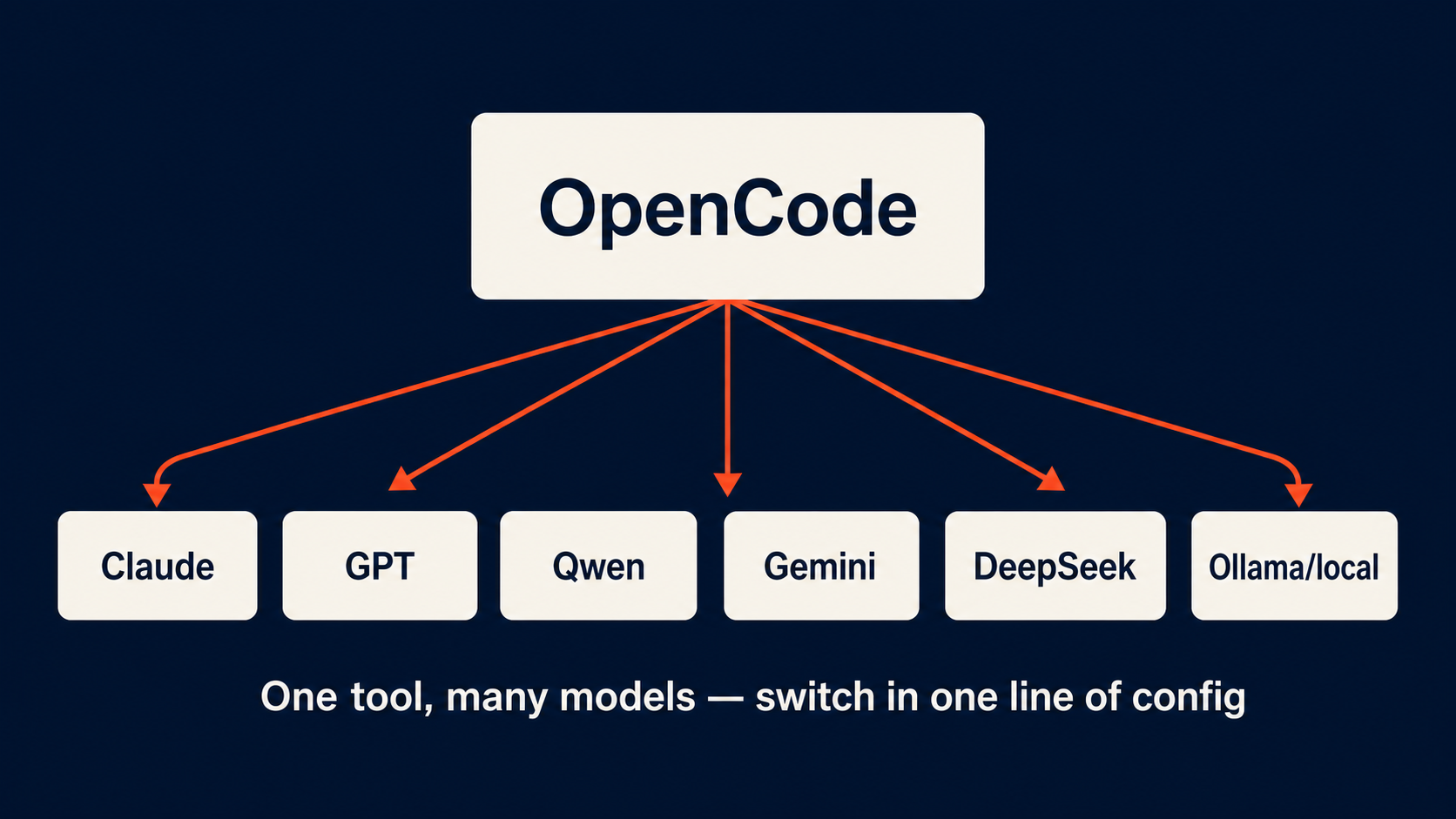
OpenCode’s architecture is the reason. It’s model-agnostic at the protocol level — 75+ providers, same interface. You configure a model provider once, and every feature of the tool works with it. No tiered feature gates based on which model you’re using. No “this only works with premium.” The LSP integration, air-gapped deployment, and multi-agent orchestration all function identically whether you’re running Claude Opus 4.7 through Anthropic’s API, Qwen 3.7 Max through OpenRouter, or a local model through Ollama.
Here’s what that looks like in practice. Switching models in OpenCode is a single config change:
| |
That’s it. Three models, three different providers, zero code changes in your workflow. When Anthropic has an outage — and they’ve had at least two significant ones in Q2 2026 alone — your team doesn’t stop. When a new model drops and benchmarks look promising, you test it against your actual codebase in 30 seconds.
Compare that to the lock-in story elsewhere. Cursor’s best features are tuned for specific models. Claude Code, despite its quality lead (blind reviews prefer its output 67% of the time), is an Anthropic product through and through. Windsurf’s Arena Mode works great — with the models they’ve optimized for. These aren’t bad tools. But they make a bet on which model is best, and you inherit that bet.
OpenCode made a different bet: that the model landscape will keep shifting, and developers should be able to shift with it.
The Model Landscape Shifts Every Quarter
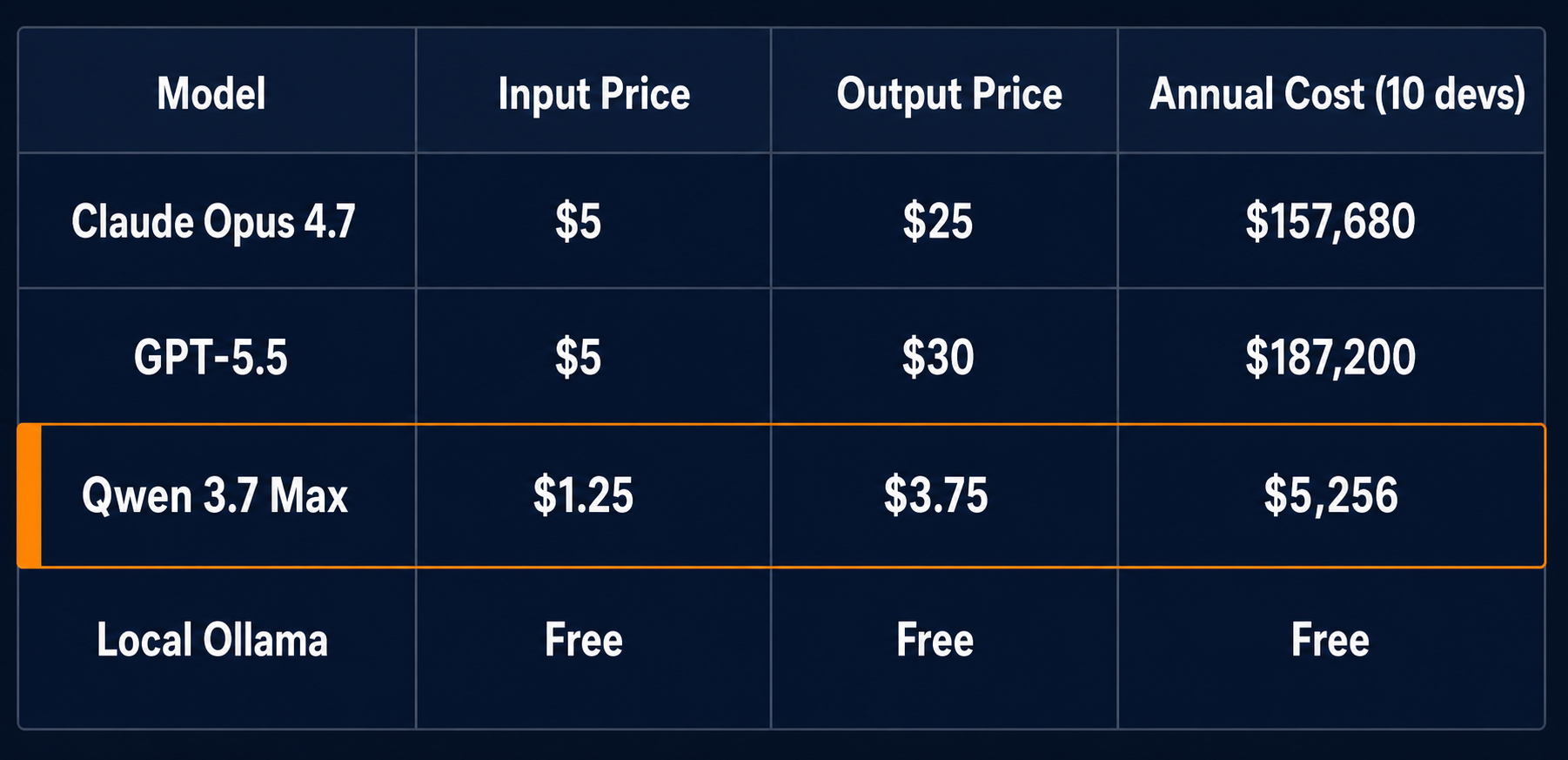
Consider the current leaderboard. Claude Opus 4.7 holds the WebDev Arena crown at 1567 Elo. GPT-5.5 leads Terminal-Bench 2.0 at 82.7%. Qwen 3.7 Max pulled off 35-hour autonomous runs with 1,158 tool calls without derailing — and costs $1.25/$3.75 per million tokens, compared to Opus 4.7’s $5/$25.
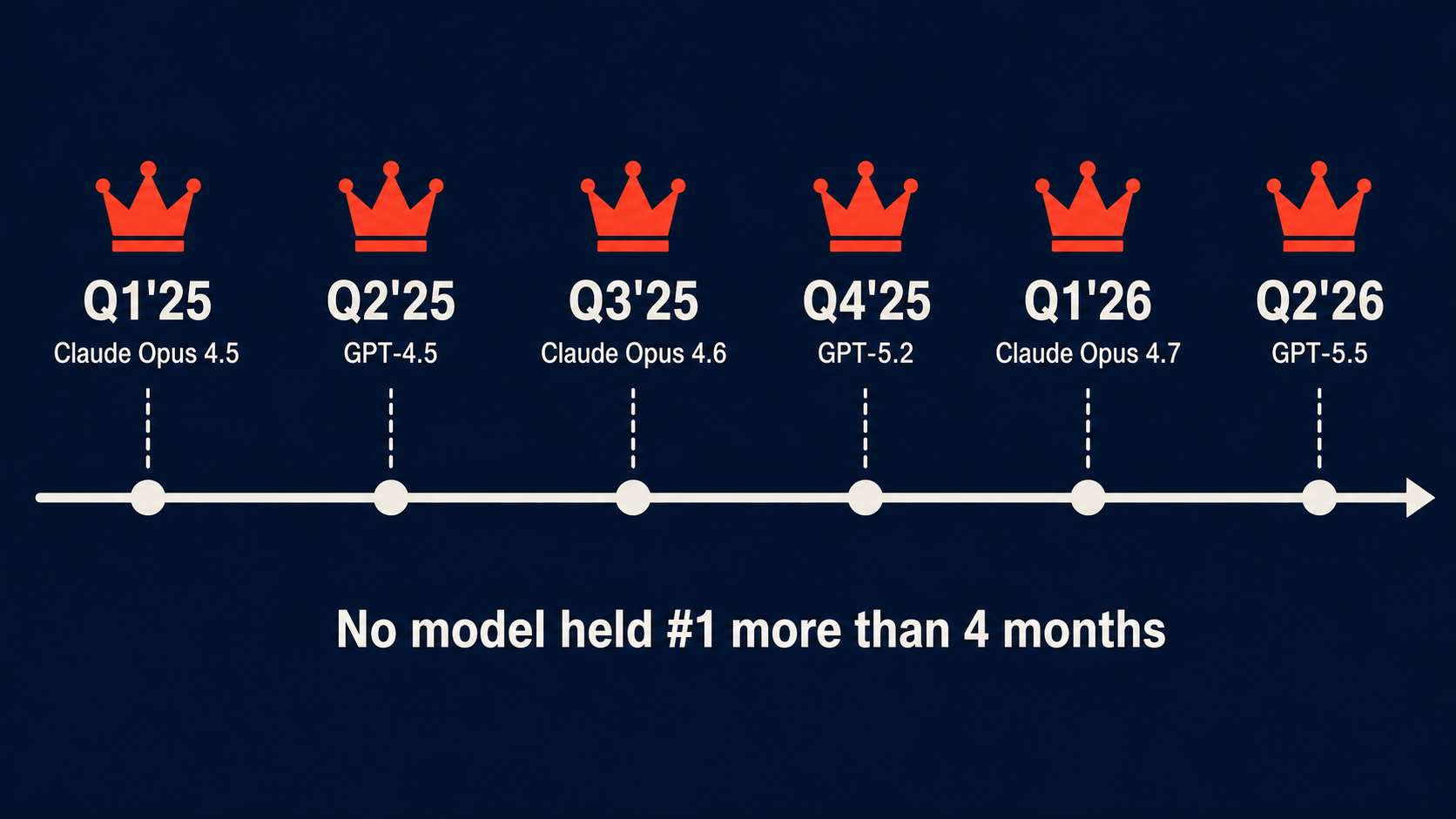
Six months ago, none of these numbers existed. Six months from now, they’ll be different. The average tenure of a #1-ranked model on any major benchmark in 2025-2026 has been roughly one quarter. If your tool is locked to a model that was #1 last quarter, you’re optimizing for a snapshot that’s already stale.
The Qwen 3.7 Max story is particularly instructive. At $1.25 per million input tokens, it delivers MCP-Atlas scores within 1% of Claude Opus 4.7 (76.4% vs 77.3%) at roughly a quarter of the price. For long-running autonomous tasks — the kind where you kick off a refactor and come back after lunch — the cost difference is material. A 35-hour session at Opus 4.7 pricing could cost hundreds of dollars. The same session on Qwen 3.7 Max might cost $30. Over a team of 20 engineers running a few autonomous sessions each per week, that’s not a rounding error.
But here’s the thing: Qwen 3.7 Max is text-only. If your workflow depends on vision capabilities — screenshots, diagrams, UI mockups — you’re back to Opus or GPT. The point isn’t that any one model is best. The point is that “best” depends entirely on what you’re doing right now.
Why 180% More Code Produces Only 30% More Software
The MIT/NBER finding deserves a closer look. Why does tripling code output produce such a modest increase in shipped software?
Part of it is the review bottleneck. Generating code is fast. Reviewing generated code is not. When an AI produces 500 lines of a feature implementation, someone still needs to read those 500 lines, understand them, test them, and integrate them. The generation time dropped to near-zero. The review time didn’t change.
Part of it is context collapse. A model locked into a single-provider setup might be excellent at isolated tasks — “write a function that parses this CSV format” — but mediocre at understanding how that function fits into a codebase with 47 other CSV parsers, each with slightly different conventions. The code is syntactically correct and functionally wrong.
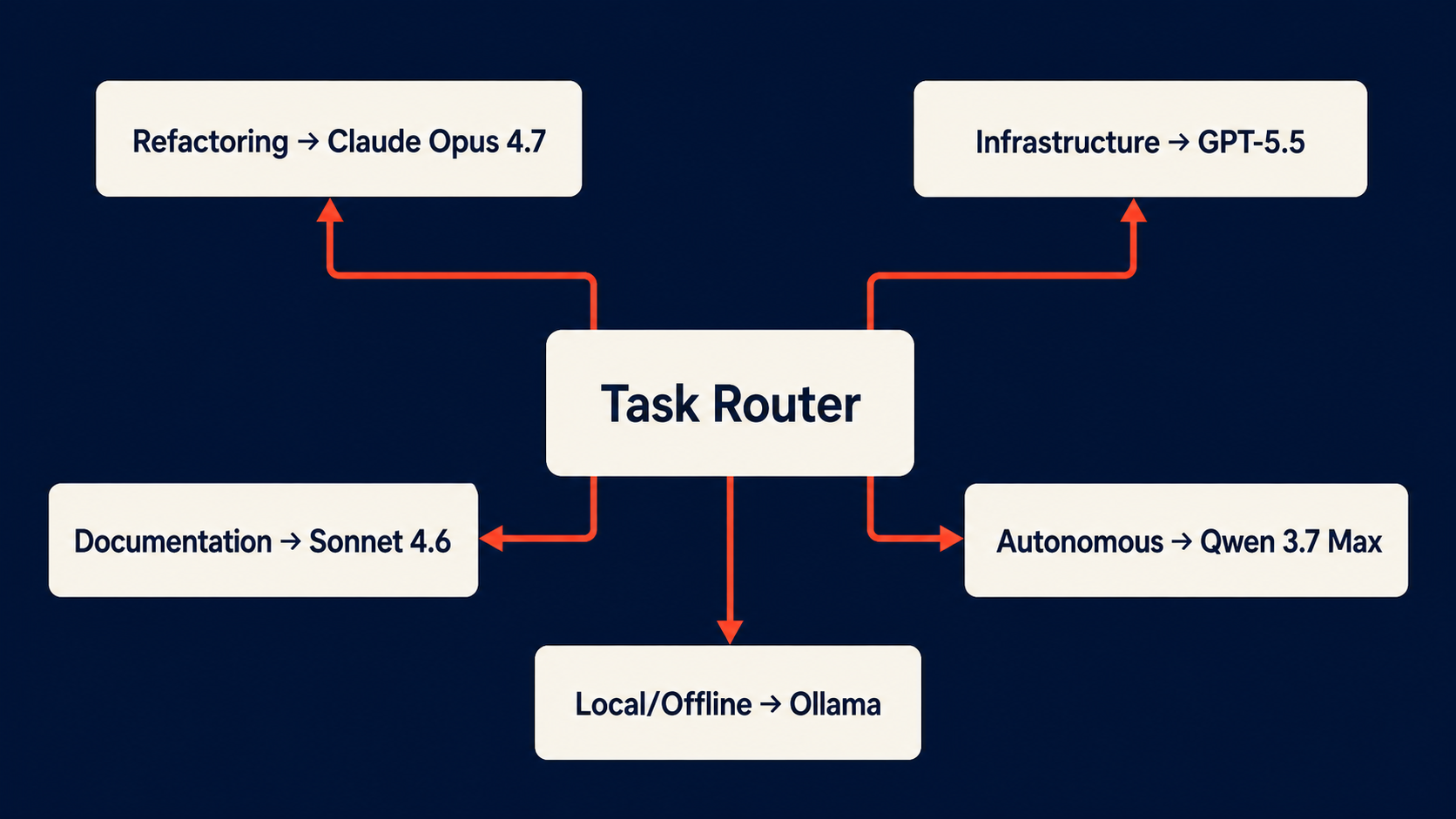
And part of it is the model mismatch problem. You’re using the same model for everything because your tool makes switching painful. That model might be great at TypeScript but mediocre at Terraform. It might nail algorithm problems but stumble on infrastructure-as-code. In a locked-in tool, you accept the mediocrity. In a portable tool, you switch models per task.
Here’s a concrete example. I have a Python script that orchestrates model selection based on the task type:
| |
This isn’t theoretical. The O’Reilly AI Agents Stack report from June 2026 identifies MCP as one of three forces that redrew the map between LLMs and production agents. The Model Context Protocol means models can now access the same tools, the same file systems, the same terminals — regardless of provider. The tool layer and the model layer are decoupled. If your tool respects that decoupling, you get portability. If it doesn’t, you get lock-in.
The Pricing Problem No One Talks About
Anthropic charges $5 per million input tokens and $25 per million output tokens for Claude Opus 4.7. OpenAI’s GPT-5.5 costs $5/$30 per million input/output tokens. Qwen 3.7 Max costs $1.25/$3.75.
These numbers seem abstract until you run them through a real workload. A medium-complexity feature — say, adding OAuth with role-based access control to an existing API — might consume 200K input tokens (the codebase context) and produce 50K output tokens (the implementation). On Opus 4.7, that’s roughly $2.25 per run. On Qwen 3.7 Max, it’s about $0.44.
Now multiply by 50 such features per sprint across a 10-person team. Opus: $1,125 per sprint. Qwen: $220. Over a year, the difference is roughly $23,500. For a single team.
But the pricing story isn’t just about which model is cheaper. It’s about pricing power. When your tool is locked to one provider, that provider sets the price and you pay it. When OpenRouter added Qwen 3.7 Max at half the cost of comparable models, OpenCode users could switch in one line of config. Cursor users — whose features are tuned for specific models — had no equivalent move.
This is vendor leverage 101. The more you build on a single model, the more you pay over time. The model-agnostic approach neutralizes that leverage. You’re not paying for the model. You’re paying for the right model for each task.
What This Means for Teams Choosing Tools Today
If you’re evaluating AI coding tools for a team in mid-2026, the criteria should be:
1. Model portability is table stakes. If a tool doesn’t support at least three model providers with feature parity across all of them, you’re making a bet you can’t hedge. The model landscape shifts quarterly. Your tool choice shouldn’t.
2. Benchmark the tool against your codebase, not the model against a leaderboard. Claude Opus 4.7’s 1567 WebDev Arena Elo is interesting. Its performance on your specific monorepo with your specific conventions is what matters. Tools that let you A/B test models on your actual code are worth 10x more than tools that promise the best model.
3. Cost-per-task beats cost-per-token. The $2.25 vs $0.87 per feature isn’t the whole story. Factor in review time, integration time, and error-correction time. The cheapest model that produces correct, mergeable code is the cheapest model — not the one with the lowest per-token price.
4. Local and air-gapped capabilities matter. OpenCode’s MIT license and air-gapped deployment aren’t just compliance checkboxes. They’re insurance against provider outages, pricing changes, and data sovereignty requirements. JetBrains’ survey data shows LangChain remains the most widely adopted agent framework, and Microsoft’s AutoGen with the A2A protocol is gaining ground — but both assume always-online, always-connected operation. That assumption breaks in regulated industries.
Here’s what an air-gapped OpenCode setup looks like:
| |
No API keys. No network calls. No third-party servers reading your code. For fintech, defense, healthcare — this isn’t optional. It’s the only mode that passes security review.
The Tool Doesn’t Matter. The Architecture Does.
Cursor has the best full-IDE experience. Claude Code produces output that wins blind reviews 67% of the time. Windsurf’s Arena Mode and parallel multi-agent orchestration are genuinely innovative. Antigravity is completely free during its preview and shows promise with multi-agent orchestration.
But none of that matters if you can’t switch models when the landscape changes — and it will change. It changes every quarter.
The tool you pick today is a multi-year commitment. Teams build workflows, integrations, CI/CD pipelines, and institutional knowledge around their coding tools. Switching tools is expensive. Switching models within a portable tool is cheap. That asymmetry is the entire argument.
OpenCode’s architecture decision — model-agnostic at the protocol level, MIT-licensed, air-gapped by default — isn’t flashy. It doesn’t make for a good benchmark score. But it’s the right architecture for a world where the best model changes faster than your sprint cycles.
Pick the tool that lets you leave when the model stops being right for you. Not the one that bets everything on a model that might not be #1 next quarter.