
If you’ve been shipping LLM-powered features for the last two years, you’ve felt it: the API bill that started as a rounding error and is now a line item your CFO asks about in weekly meetings. The model providers built beautiful APIs, priced them per token, and we all built businesses on top of usage-based pricing that only goes in one direction — up.
That assumption broke last week.
Z.ai released GLM-5.2 under the MIT license — full open weights, no usage restrictions, HuggingFace download — and it benchmarked competitively against GPT-5.5 on the tasks that matter for production: long-horizon coding, agentic tool use, and multi-step software engineering. The cost difference isn’t marginal. On OpenRouter, GLM-5.2 runs $0.95 per million input tokens and $3.00 per million output tokens. GPT-5.5 standard pricing is $5.00/$30.00 per million. [Source: https://openrouter.ai/z-ai/glm-5.2] [Source: https://openai.com/api/pricing]
That’s roughly a 6× cost gap on tokens alone. But the real story isn’t the price — it’s the portability. When the weights are open and MIT-licensed, you have an exit ramp. You can self-host. You can negotiate. You can switch providers without rewriting your application layer. That changes how you architect.
For a practical engineering team building developer tooling with heavy code generation and agentic workflows, the question is simple: which parts of the stack should move to open weights now, and which parts should stay on the premium proprietary API? Here’s the decision framework.
The Cost Math That Actually Matters
Let’s get the numbers on the table. Here’s a like-for-like comparison using current public pricing as of late June 2026:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context Window | License |
|---|---|---|---|---|
| GLM-5.2 (OpenRouter) | $0.95 | $3.00 | 1,048,576 | MIT (open weights) |
| GPT-5.5 (Standard) | $5.00 | $30.00 | 256,000 | Proprietary |
| GPT-5.5 (Batch/Flex) | $2.50 | $15.00 | 256,000 | Proprietary |
[Source: https://openrouter.ai/z-ai/glm-5.2] [Source: https://openai.com/api/pricing]
GLM-5.2 is a 753B-parameter Mixture-of-Experts model with approximately 40B active parameters per forward pass and a 1-million-token lossless context window — a 5× increase over its predecessor GLM-5.1’s 200K limit. [Source: https://docs.z.ai/guides/llm/glm-5.2]

Now let’s make this concrete with a real workload. Say you’re running a code assistant that processes 50 million input tokens and generates 10 million output tokens per day — a moderate team usage pattern for an agentic coding tool:
| |
Run that script yourself — it’s plain Python, no dependencies. The numbers speak: GPT-5.5 standard costs 7.1× more than GLM-5.2 on OpenRouter for the same token volume. Even GPT-5.5’s cheapest batch tier is still 3.5× more expensive.
But here’s what the raw price-per-token doesn’t capture: with GLM-5.2, that $2,325/month on OpenRouter is the ceiling, not the floor. With open weights, you have the option to bring it lower.
What Open Weights Actually Buy You
The license matters more than the benchmark. MIT means you can download the weights, modify them, host them commercially, and distribute derivatives — no royalty, no call-home requirement, no usage cap. The weights are on HuggingFace at zai-org/GLM-5.2. [Source: https://huggingface.co/zai-org/GLM-5.2]
Here’s what that unlocks in practice:
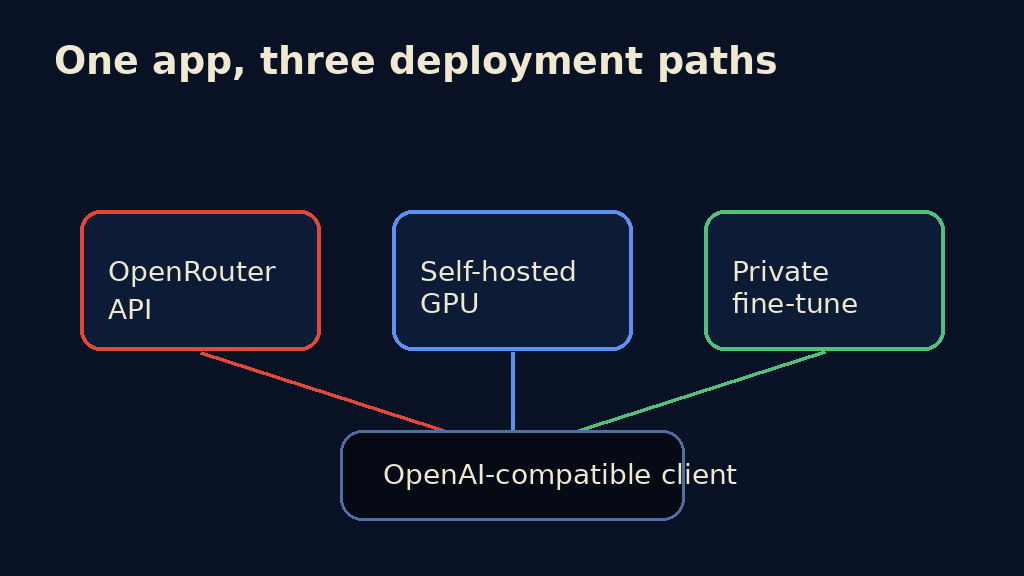
1. Negotiating leverage. Right now, if you want GPT-5.5, you go to OpenAI. That’s the only source. When your volume grows, you can’t shop the price. With GLM-5.2, there are already 23+ providers on OpenRouter alone [Source: https://openrouter.ai/z-ai/glm-5.2], and you can self-host on any GPU cloud. If one provider raises prices, you switch in a single API call — the OpenAI-compatible endpoint stays the same.
2. Predictable cost floors. API pricing can change. When you have the weights, you know the actual cost of running inference: it’s GPU-hours × time. At FP8 precision, GLM-5.2 needs roughly 744 GB of VRAM. [Source: https://huggingface.co/blog/zai-org/glm-52-blog] That’s a lot — but it’s a fixed, knowable number. On a multi-GPU H100 node, you can calculate your cost per token to the cent.
3. Data sovereignty. For teams in regulated industries or specific jurisdictions (including here in Indonesia), the ability to run inference on your own infrastructure matters. No tokens leave your network. No provider logs your prompts.
4. Fine-tuning and customization. You can’t fine-tune a model you can’t access the weights for. GLM-5.2 being open means you can adapt it to your codebase, your language, your domain — and nobody can revoke that capability.
The pragmatic question isn’t “should I switch everything to open weights?” — it’s “what does my architecture look like when I have a real choice?”
The Benchmark Reality Check (Without the Hype)
I’m not going to pretend the benchmarks don’t matter. They do — but only as a gating condition, not as a selection criterion. A model that’s 10% cheaper but can’t actually complete the tasks you need it for is more expensive, not less.
Here’s where GLM-5.2 landed on the benchmarks that correlate with real developer workloads:
| Benchmark | GLM-5.2 | GLM-5.1 | GPT-5.5 |
|---|---|---|---|
| SWE-bench Pro | 62.1 | 58.4 | 58.6 |
| Terminal-Bench 2.1 | 81.0 | 63.5 | — |
| VibeCodeBench | 63.96% | 31.46% | — |
[Source: https://venturebeat.com/technology/z-ais-open-weights-glm-5-2-beats-gpt-5-5-on-multiple-long-horizon-coding-benchmarks-for-1-6th-the-cost] [Source: https://kie.ai/blog/glm-5-2-benchmark-deep-dive]
SWE-bench Pro is the one I pay attention to. It measures whether a model can autonomously resolve real GitHub issues — the kind of task that maps directly to “is this useful in my CI pipeline?” GLM-5.2 scored 62.1, decisively ahead of GPT-5.5’s 58.6 and its own predecessor’s 58.4. [Source: https://venturebeat.com/technology/z-ais-open-weights-glm-5-2-beats-gpt-5-5-on-multiple-long-horizon-coding-benchmarks-for-1-6th-the-cost]
Terminal-Bench is the other one worth watching. GLM-5.2 jumped from 63.5 to 81.0 in a single generation — that’s the agentic terminal-use benchmark, measuring multi-step command-line reasoning. [Source: https://apidog.com/blog/glm-5-2-benchmarks/]
These numbers are from Z.ai’s own evaluation runs and third-party analyses. I’m citing them — I’m not claiming to have independently reproduced them. What I can say is that the direction is clear: GLM-5.2 is in the same performance tier as GPT-5.5 for agentic coding tasks, not a step behind. That’s the gating condition. It cleared it.
The decision question is no longer “is the open model good enough?” It’s “given that the open model is good enough, what does the cost gap mean for my unit economics?”
Architecture Patterns for the Open-Weights Era
The mistake teams make with open-weights models is treating them as a drop-in replacement for a single provider API. That works for a prototype, but it throws away the actual advantage. Here are three patterns I’m implementing:
Pattern 1: The Router Layer
Don’t hardcode a single model. Build a routing layer that can direct requests to different providers based on task type, cost, and latency requirements. This is trivial with OpenRouter as an intermediary, but you should also support direct connections to self-hosted instances for sensitive workloads.
| |
The key insight: because GLM-5.2’s API (both on OpenRouter and when self-hosted via vLLM/SGLang) is OpenAI-compatible, your application code doesn’t change when you switch backends. You’re not locked in — you’re choosing every time you make a call.
Pattern 2: Cost-Aware Caching
With a 6× price gap, caching decisions change. Something you’d accept recomputing on GPT-5.5 because “it’s just one call” becomes meaningful when you realize the same cache miss costs 6× on the expensive model. But more importantly: with a 1M context window, you can keep entire codebases in context and avoid the per-call overhead of re-sending them.
| |
Pattern 3: Hybrid Workload Splitting
Not every call needs the same model. Routine code completion, boilerplate generation, and simple refactoring can run on cheaper tiers. Reserve the expensive models for tasks where they genuinely add value — complex reasoning, novel architecture, safety-critical decisions.
Self-Hosting: When It Actually Makes Sense
Let me be direct about this: self-hosting GLM-5.2 is not a Monday-morning project for most teams. The model is 744 GB at FP8, roughly 1.5 TB unquantized. [Source: https://huggingface.co/zai-org/GLM-5.2] You need serious GPU hardware.
Here’s a basic vLLM deployment for when you’re ready:
| |
[Source: https://docs.z.ai/guides/llm/glm-5.2]
When does self-hosting cross the break-even line? Rough math: an 8× H100 node on a major cloud GPU provider runs approximately $20-30/hour. At GLM-5.2’s OpenRouter pricing of $0.95/$3.00 per million tokens, you’d need to be spending roughly $15,000-20,000/month on API calls before self-hosting on a dedicated node becomes cheaper. For most teams, the API route via OpenRouter is the right starting point. For high-volume teams or those with data sovereignty requirements, the exit ramp exists.
SGLang is the alternative inference engine, and for this model specifically it shows slightly better throughput on agentic workloads due to its radix-attention caching. Both vLLM and SGLang are officially supported by Z.ai. [Source: https://docs.z.ai/guides/llm/glm-5.2]
What You Should Do Monday Morning
Here’s the concrete action list, ordered by effort and impact:
1. Switch your non-critical coding workloads to GLM-5.2 on OpenRouter. This is a single environment variable change if you’re using an OpenAI-compatible client. Point your base_url at https://openrouter.ai/api/v1, set the model to z-ai/glm-5.2, and run your existing test suite. If your prompts work, you’re now paying 1/6th per token. If they don’t, you’ve lost 30 minutes.
2. Build the router layer. Even if you start with just two backends (GLM-5.2 as primary, GPT-5.5 as fallback), having the abstraction means you’re never locked in again. The code I showed above is 40 lines. Ship it.
3. Run a 48-hour shadow test. Route 10% of your production traffic to GLM-5.2 alongside your current provider. Log the outputs. Compare quality. Don’t make a full switch based on benchmarks — make it based on your actual tasks. The benchmarks tell you it’s in the same tier; only your workload tells you if it’s the right fit.
4. Calculate your break-even. Track your current monthly token spend. If it’s under $5K/month, the OpenRouter API is your answer — don’t overthink it. If it’s $15K+/month, start planning the self-hosting pilot. Get quotes from GPU cloud providers and compare against your API bill.
5. Audit your prompt strategy for the 1M context window. GLM-5.2 supports up to 1,048,576 tokens of context [Source: https://docs.z.ai/guides/llm/glm-5.2]. That changes how you handle large codebases. Instead of chunking and losing context, you can load an entire repository and let the model reason across files. This is a capability shift, not just a cost shift.
The Market Signal Nobody’s Talking About
Here’s what I think actually happened last week, from a developer’s perspective: the margin structure of frontier LLM APIs broke.
For two years, the implicit deal was: “We train the model, we host the model, you pay per token. The per-token price includes our training cost, our infrastructure cost, and a healthy margin.” That margin was defensible because there was no alternative — the closed models were the only ones good enough.
GLM-5.2 changes that. Not because it’s slightly better on a benchmark — benchmarks come and go. But because it proved that an open-weights model can sit in the same performance tier as the most expensive proprietary option while costing 6× less to run. The weight is on HuggingFace. The license is MIT. The inference engines are open source. Every single layer of the stack is commoditizable.
This puts downward pressure on all API pricing, not just GLM-5.2’s. When OpenAI knows a customer can point their base_url elsewhere and get equivalent results for 1/6th the price, the pricing power shifts. We’re already seeing it — GPT-5.5’s Batch/Flex tier at $2.50/$15.00 is exactly the kind of price discrimination that only exists when there’s a credible alternative. [Source: https://openai.com/api/pricing]
The teams that benefit most won’t be the ones who pick a single model and commit. They’ll be the ones who build architectures that treat models as interchangeable, cost-aware components. The model is not the product. The pipeline is.
Further Reading
- Z.ai GLM-5.2 Official Documentation — Context window, tool calling specs, and deployment guides: https://docs.z.ai/guides/llm/glm-5.2
- VentureBeat: GLM-5.2 Beats GPT-5.5 on Coding Benchmarks at 1/6th Cost — The original report with full benchmark breakdown: https://venturebeat.com/technology/z-ais-open-weights-glm-5-2-beats-gpt-5-5-on-multiple-long-horizon-coding-benchmarks-for-1-6th-the-cost
- HuggingFace Model Card (zai-org/GLM-5.2) — Weights, evaluation logs, and usage terms: https://huggingface.co/zai-org/GLM-5.2
The cost gap is real. The capability gap isn’t. Build accordingly.