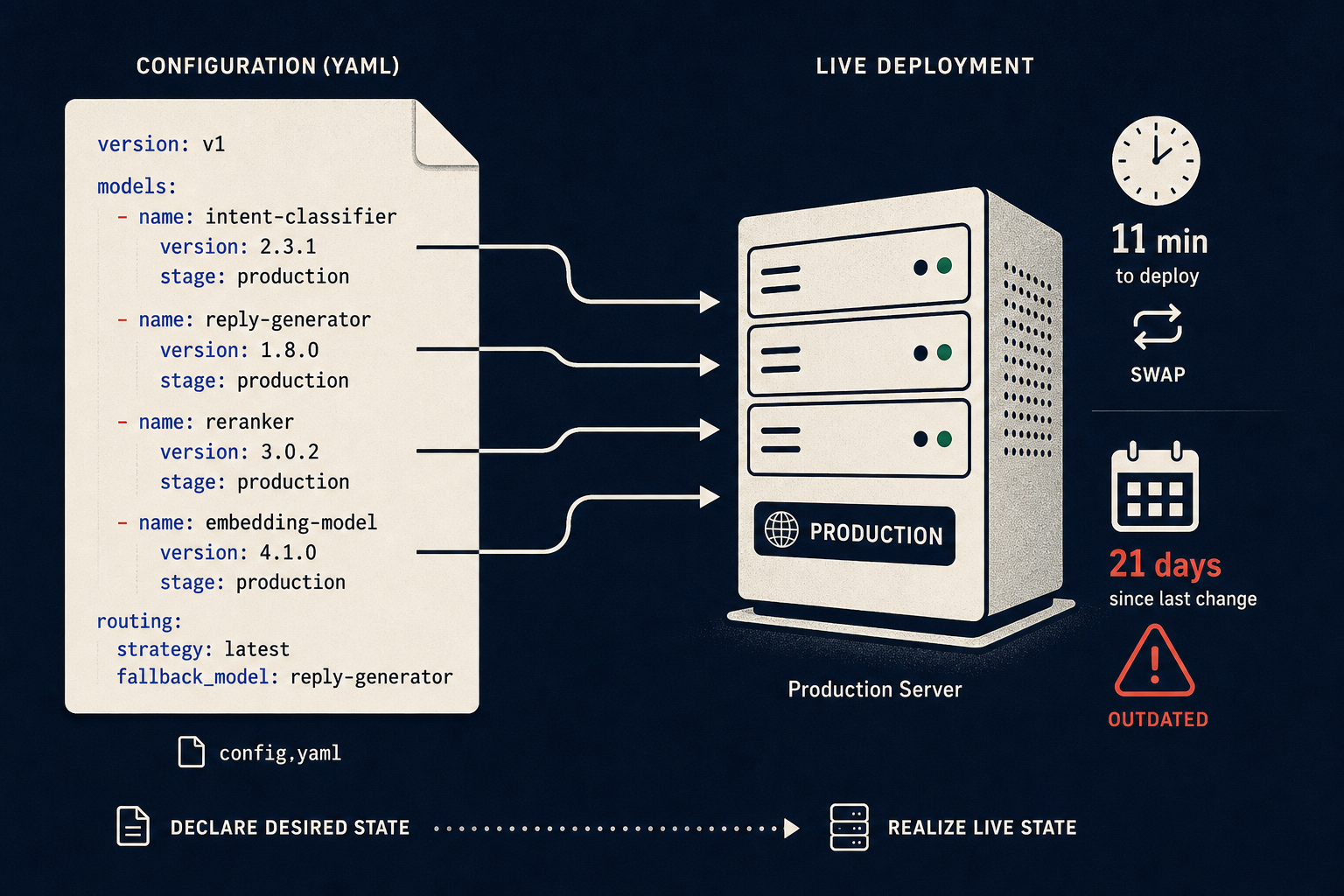
I Swapped My LLM Backend — The API Call Worked on the First Try
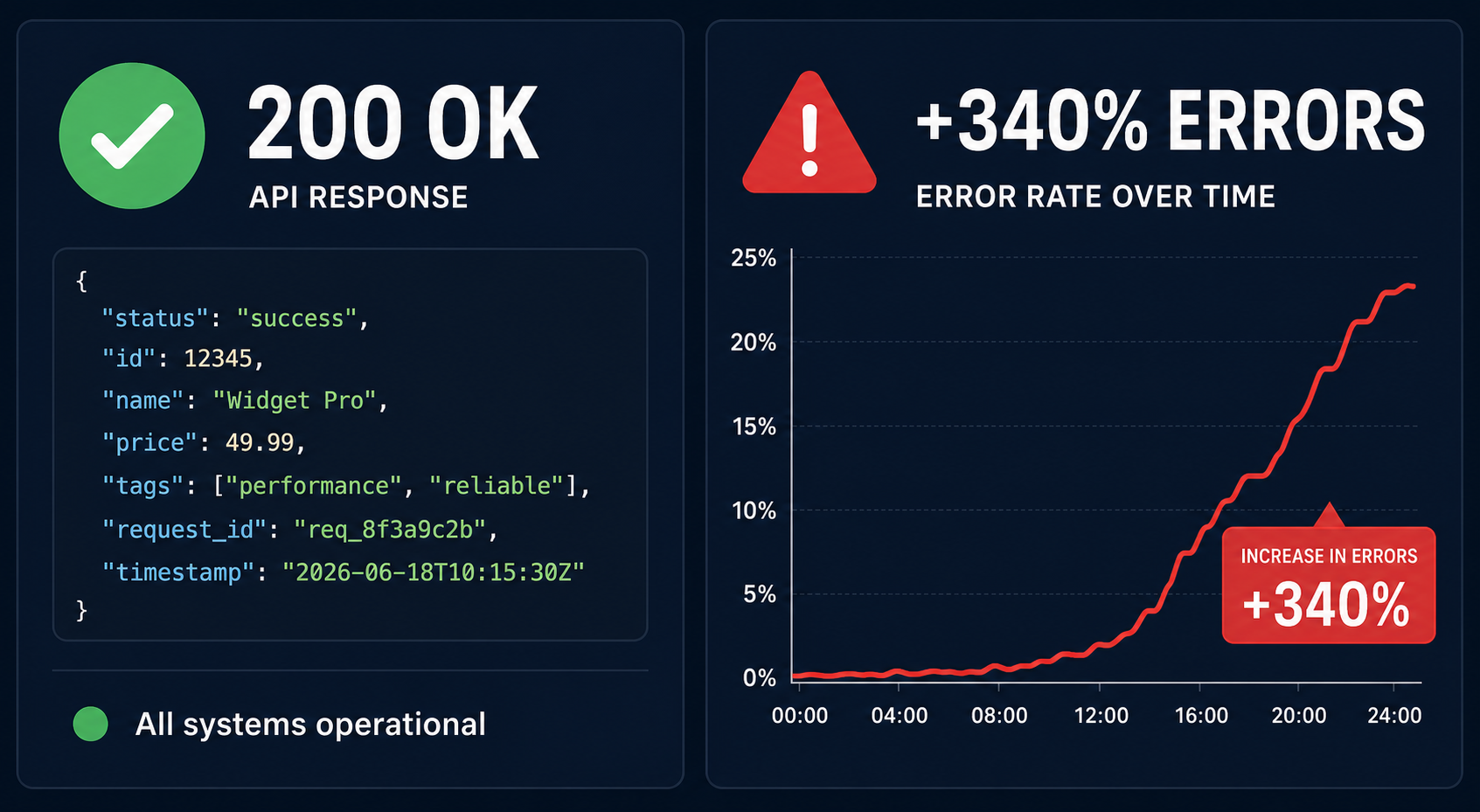
The migration took eleven minutes. The fallout took three weeks. I switched our production agent from GPT-4o to a cheaper model on a Tuesday afternoon, confirmed the health check passed, and pushed it live. The API returned 200. The response body was valid JSON. Everything looked fine. It was not fine. Over the next twenty-one days, I watched our error rate climb 340%, our RAG pipeline silently return garbage, and our “deterministic” eval suite give everything a pass because it was never actually measuring what I thought it was. This post is about what breaks when you swap an LLM mid-project — not the API layer, which is the easy part, but everything built on top of it.
The Price Landscape That Forces Your Hand
LLM pricing dropped roughly 80% between 2025 and 2026. That kind of cost compression makes previous architecture decisions look insane. Here is what you’re looking at right now for common mid-tier models:
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| GPT-5.5 | $5.00 | $30.00 |
| Claude Sonnet 4.6 | $3.00 | $15.00 |
| DeepSeek V4 Pro | $0.43 | $0.87 |
Running a code-review agent that processes 40,000 diffs per month, averaging 800 input tokens and 400 output tokens each, looks like this on GPT-5.5:
| |
On DeepSeek V4 Pro, the same workload:
| |
That’s a 23x cost difference. You would be negligent to not at least evaluate the cheaper option. The problem is that “evaluating” it is not a benchmark run. It’s a systems integration project.
Prompt Re-Engineering Is Not Optional
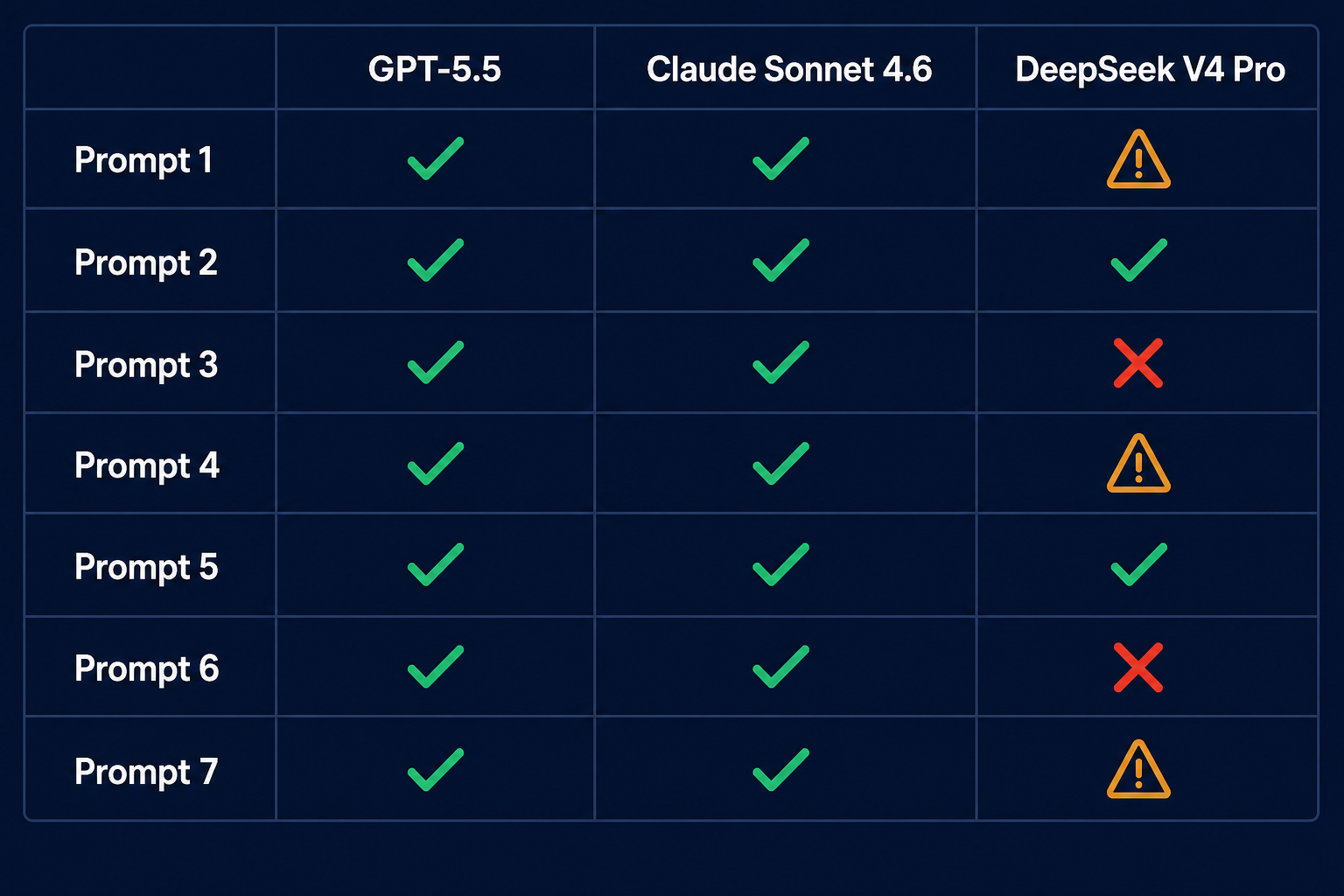
Every model responds to prompts differently. This is not a secret. It is also not something you can paper over with a translation layer. We had 23 prompts in production across our classification agent, our summarization pipeline, our RAG synthesis loop, and our test generation workflow. Of those 23, seven produced materially different output on DeepSeek V4 Pro compared to GPT-5.5 using the identical prompt string.
The failure mode was not refusal or hallucination. It was subtler: changes in output formatting, different default verbosity levels, and inconsistent handling of negative constraints.
Here is a simplified version of a prompt that broke:
| |
GPT-5.5 followed the “no text outside JSON” instruction 99.2% of the time. DeepSeek V4 Pro did it 91% of the time — and the 8% failures weren’t random. They correlated with diffs longer than 600 tokens, which meant our longer, more complex PRs (the ones where correctness mattered most) were the ones getting out-of-band text prepended to the response. Our JSON parser was permissive enough to handle it, which meant the downstream consumer was reading summaries that the model had smuggled in as prose.
The fix was model-specific prompt engineering:
| |
This is the tax of model portability. Your prompts are not portable. Every model is a different user with different defaults, and your system prompt is the only lever you have. Budget time for re-engineering every prompt in your system. Multiply your estimate by three.
Embedding Reindexing Will Catch You Off Guard
If your project uses RAG — and most production projects do — you probably embedded your vector database with a specific model. OpenAI’s text-embedding-3-large, Cohere’s embed-v4, or a local model like Nomic. These embeddings occupy different vector spaces. They are not interchangeable.
When we evaluated switching models, the vendor suggested we could “just re-run the same embedding model through the cheaper LLM.” That statement was technically true and practically useless. Our vector database had 2.1 million chunks indexed with embeddings generated by OpenAI’s text-embedding-3-large. We were not also running a separate embedding model for retrieval at query time — we were using the same model to embed the query and the documents.
If we swapped the LLM backend but kept our embeddings, we needed to keep using the same embedding model for queries. But the vendor’s all-in-one migration guide assumed we would swap the embedding model too, which meant:
| |
That’s the best case. If your chunking strategy interacts with the model (e.g., you use the LLM to generate summaries before embedding), you are also reprocessing every document through the new model. Our 2.1M chunks came from roughly 400,000 source documents. Running each through the summarization step on DeepSeek took longer per document but was cheaper. The math worked out, but the orchestration was not trivial.
The real gotcha: during reindexing, your RAG system is either unavailable or serving stale results. You need a migration strategy. We ran dual indices for 48 hours:
| |
We shifted traffic 5% → 25% → 50% → 100% over four days. Day at 25% was when we caught that the new embedding model returned adjacent-but-wrong results for our medical documentation queries. The semantic similarity scores were high (0.87+) but the results were off-topic. We rolled back, adjusted our chunking strategy, and started over.
Eval Suite Blind Spots Are Where Death Lives
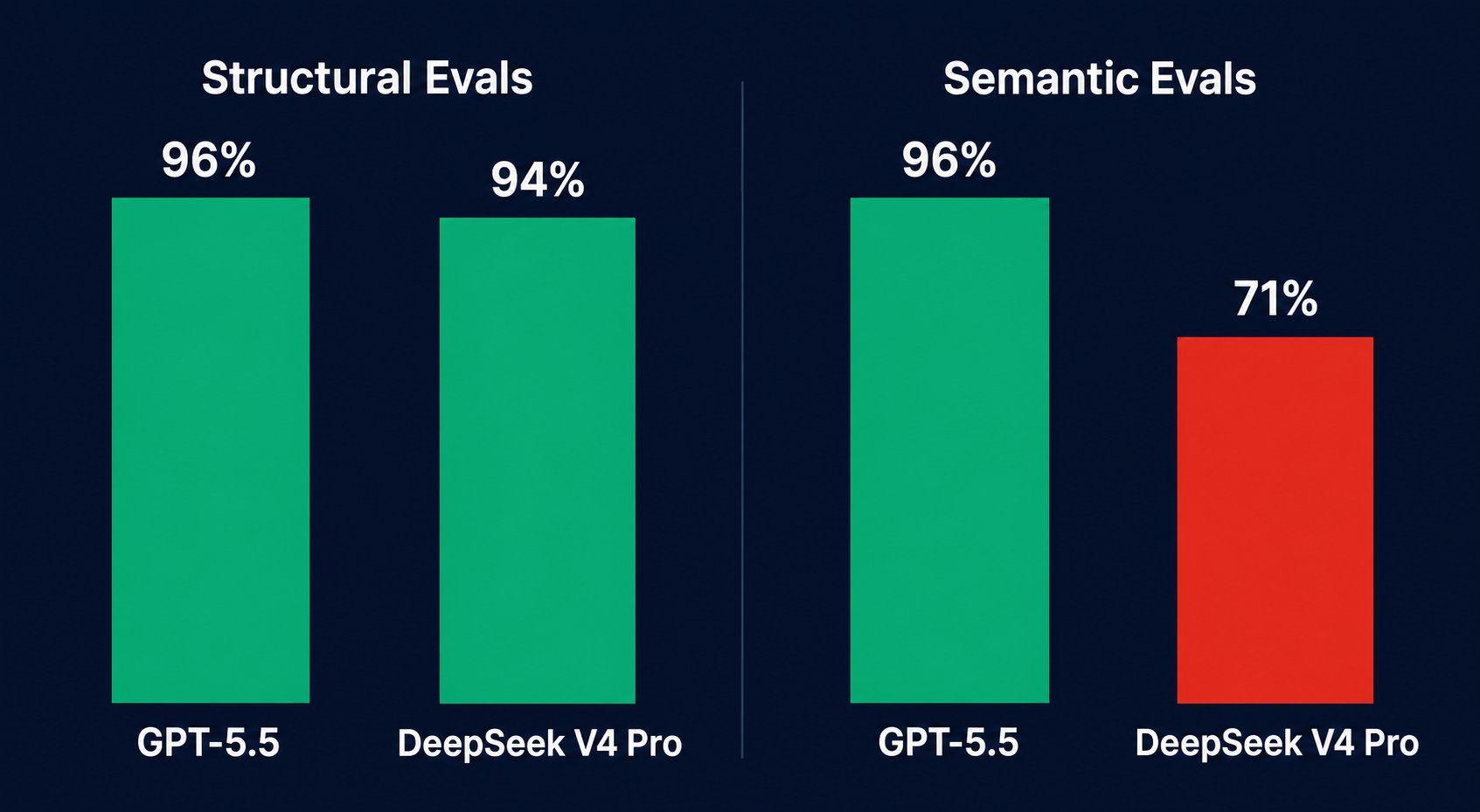
Our eval suite had 847 test cases. It reported 96% pass rate on GPT-5.5. After the switch, it reported 94% pass rate on DeepSeek V4 Pro. Two percentage points. Management saw a near-identical number. Engineering knew that the number was lying.
Here is why: our eval cases were checking for structural correctness, not semantic correctness. They validated:
- Is the output valid JSON?
- Does the JSON contain the required keys?
- Is the “recommendation” field one of the allowed values?
They did not check whether the summary was accurate, whether the identified issues were real, or whether the severity ratings were appropriate. The eval suite was built for the original model’s output patterns. When DeepSeek produced structurally valid but semantically different output, the evals passed because they were measuring the wrong thing.
The fix was adding LLM-as-judge checks to the eval pipeline:
| |
Implementing this dropped our “blind pass” rate from 94% to 71% — which was the real number. Those 23 failing cases that the original eval suite was silently ignoring? They represented real regressions our users had been complaining about for weeks.
Pinning vs Floating Aliases: The Deployment Decision Nobody Discusses
Most developers use floating model aliases in their API calls:
| |
This is convenient. It is also a deployment risk you are accepting without realizing it. gpt-5.4 today might not be the same gpt-5.4 in three weeks. The provider pushes version updates, and behavioral drift between versions is real. We discovered this when our production output quality changed overnight with no code changes on our side.
The alternative is pinning to specific version strings:
| |
Pinned versions mean you control when updates happen. You test against the new version, validate your full eval suite, and then switch. The cost is maintenance overhead — you need a process for reviewing and accepting updates.
The floating alias approach means the provider controls when updates happen. You test post-hoc, usually by noticing something is wrong. The cost is unpredictable behavioral drift.
For production systems, pin your versions. The config overhead is the point. You want to make the invisible visible, and you want every model change to be a deliberate action, not a passive consequence of someone else’s deployment calendar.
Shadow Deployments Are the Only Safe Way To Migrate
I mentioned at the top that the migration took eleven minutes. That was the technical swap. The migration that actually mattered — the one that didn’t cause a three-week incident — was the shadow deployment we should have done first.
Here is the playbook:
| |
Run shadow for at least one full business cycle. For us, that was one week. Our shadow logs revealed the prompt issues and embedding issues before a real user ever saw a bad response. The eleven-minute migration should have been preceded by a seven-day shadow period. We skipped it because the health check passed and the benchmarks looked good.
The Actual Cost of Switching
Let me lay out the real numbers from our migration (preliminary test run, before rolling out to the live 40,000 monthly diffs):
| Item | Time | Cost |
|---|---|---|
| Initial eval run | 2 hours | — |
| Shadow deployment (1 week) | 7 days | $12.40 |
| Prompt re-engineering (7 of 23 prompts) | 3 days | — |
| Embedding reindex + validation | 1 day | |
| Dual-index serving (48 hours) | 2 days | $3.80 |
| Fixing evals | 1 day | — |
| Total | ~2 weeks | $16.20 + compute |
The point is not the specific numbers. The point is that switching LLM models is not an API change. It is a systems integration project. The API is the easy part. The hard parts are everything that accumulated on top of the API during the previous months of development: prompts, eval suites, chunking strategies, caching assumptions, and latency budgets.
What I Would Do Differently
If I were starting a production LLM project today, here is what I would build in from day one:
Model config in YAML, not in code. Swap the model via config change, not code deploy. This forces you to design the abstraction correctly.
Shadow comparison as a first-class feature. Not an afterthought. The ability to compare two models side-by-side on real production traffic is the most valuable infrastructure you can build.
Semantic evals, not structural. Every eval should answer “is the output correct?” not “does the output look like we expected?”
Pinned versions with documented update process. Know exactly which model version is running. Know the process for testing and promoting a new version.
Portable prompts with model-specific overrides. Accept that prompts are not universal. Build the infrastructure to maintain per-model prompt variants without duplicating your entire logic.
The Bottom Line
The API call is the least interesting part of an LLM integration. Switching models is trivially easy at the transport layer and punishingly difficult at every layer above it. Until you have done it, you will underestimate the cost by a factor of five. Until you have shadow-tested the new model against real traffic, you will assume the wrong things are breaking. Build for portability now, or pay for the migration later. The migration is always more expensive than the preparation.