Every AI agent framework comparison chart tells the same story: LangGraph gets five stars for state management, CrewAI wins on developer velocity, AutoGen scores high on multi-agent conversations, and Claude Code’s SDK gets a special mention for being “Anthropic-native.” Clean. Orderly. Rows and columns that make the decision look straightforward.
They’re not wrong. They’re just answering the wrong question.
Nobody asks what happens at 3AM when the cron job fires, the agent spawns a subagent, and three hours later nothing has completed but every metric reports green. Nobody asks why the LLM-powered router burned $12 in tokens deciding what to do next — before any actual work started. Nobody asks what happens when an agent with free-roaming access to your codebase starts making connections between files that have nothing to do with each other, drifts off-spec, and confidently ships the wrong thing.
I run autonomous agent cron pipelines. Enough of them to know that the frameworks comparison charts are what you read before you deploy. The rest of this post is what you learn after — sometimes the hard way, sometimes from developers like Nathaniel Hamlett, who runs 23 autonomous cron jobs cycling through discovery, research, and output stages without human intervention.
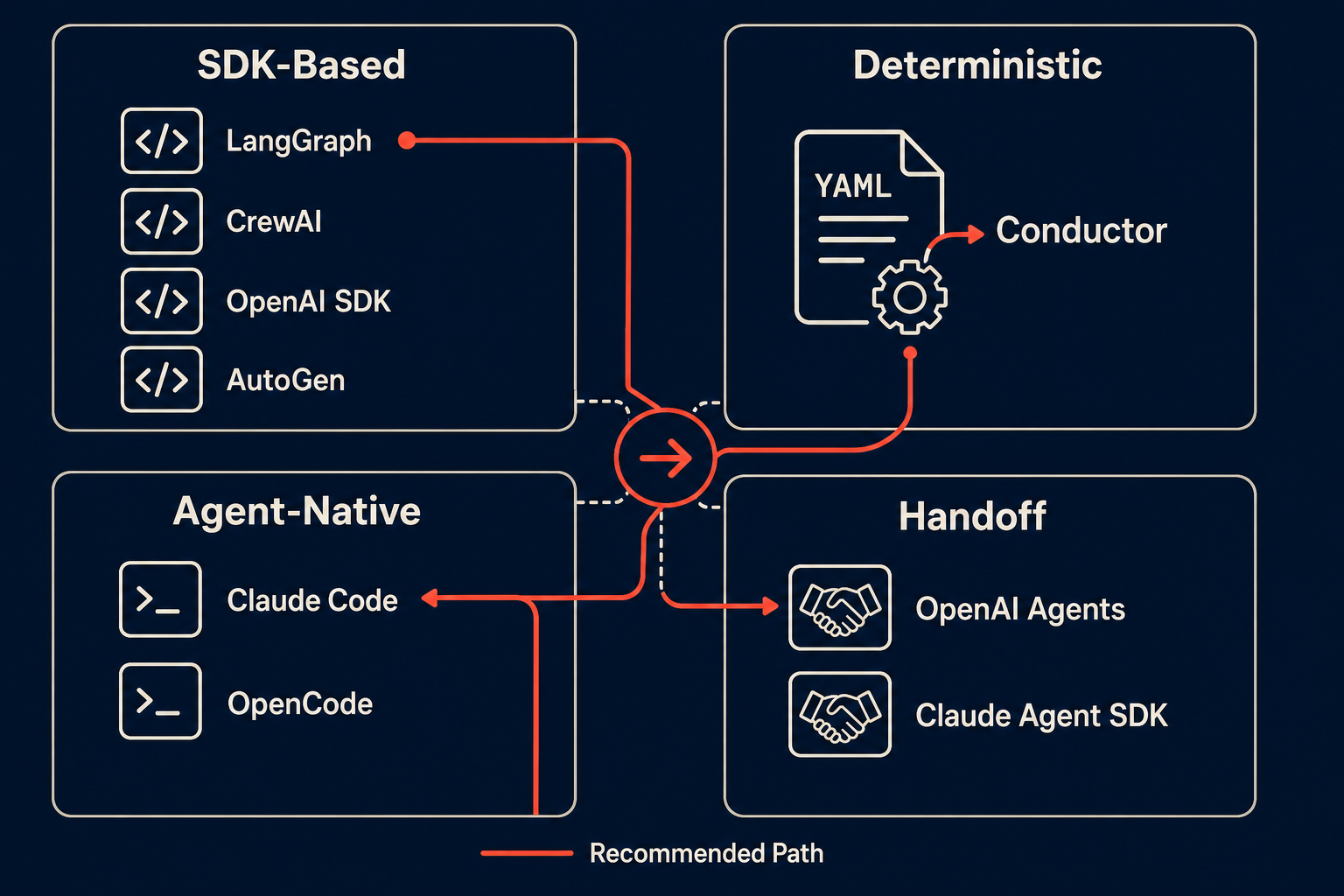
The Framework Landscape, Organized by What Actually Matters
Most comparisons group frameworks by GitHub stars or release date. Group them by orchestration model instead — it’s the one axis that predicts production behavior.
Graph-based orchestration. LangGraph is the reference here. You define nodes and edges explicitly. The agent follows a directed graph. Branching, retries, and human-in-the-loop checkpoints are first-class concepts. As JetBrains noted in their 2026 framework guide, this model provides “more deterministic control” and makes debugging easier because you “pinpoint exactly which node failed.” The tradeoff: more upfront design. The graph constrains what the agent can do, which is exactly the point — and exactly why it works in production.
Role-based orchestration. CrewAI and AutoGen dominate this category. You assign roles — Researcher, Writer, Reviewer — and let agents collaborate through conversation. CrewAI is the fastest path from idea to prototype. Alice Labs ranked it #3 overall for production deployments, noting its “very low barrier to entry” and “built-in primitives for sequential and hierarchical workflows.” AutoGen pioneered the conversational multi-agent paradigm but split into two lineages in 2025: Microsoft’s v0.4+ rewrite and the community fork AG2 (ag2.ai). Pick deliberately — they share DNA but not APIs.
Handoff-based orchestration. The OpenAI Agents SDK and Claude Agent SDK represent the managed/hosted approach. OpenAI provides the orchestration infrastructure; you define agent behavior. Claude Agent SDK, as Alice Labs documented, is “the same architecture that powers Claude Code” — hooks, MCP, skills, subagents. It’s Anthropic-native, which means it’s optimized for Claude models, not model-agnostic. The upside is deep integration. The downside is vendor lock-in, and if Claude goes down overnight (as happened with Fable 5), your pipeline stops.
YAML/deterministic orchestration. Microsoft Conductor takes the contrarian position. No LLM in the routing loop. You define workflows in YAML. Jinja2 templates handle conditions and branching. The orchestration layer costs zero tokens. As Microsoft’s open-source blog put it in May 2026: “most frameworks use LLM as orchestrator (dynamic planning) — adds cost, latency, unpredictability.” Conductor says: skip that. Route deterministically, spend tokens only inside tasks.
That’s the landscape on paper. Here’s what breaks.
What Actually Breaks in Production
Traditional software fails loudly. Stack traces. Exceptions. Pagers. Autonomous agents fail quietly. The process stays alive, the heartbeat keeps ticking, but no work gets done.
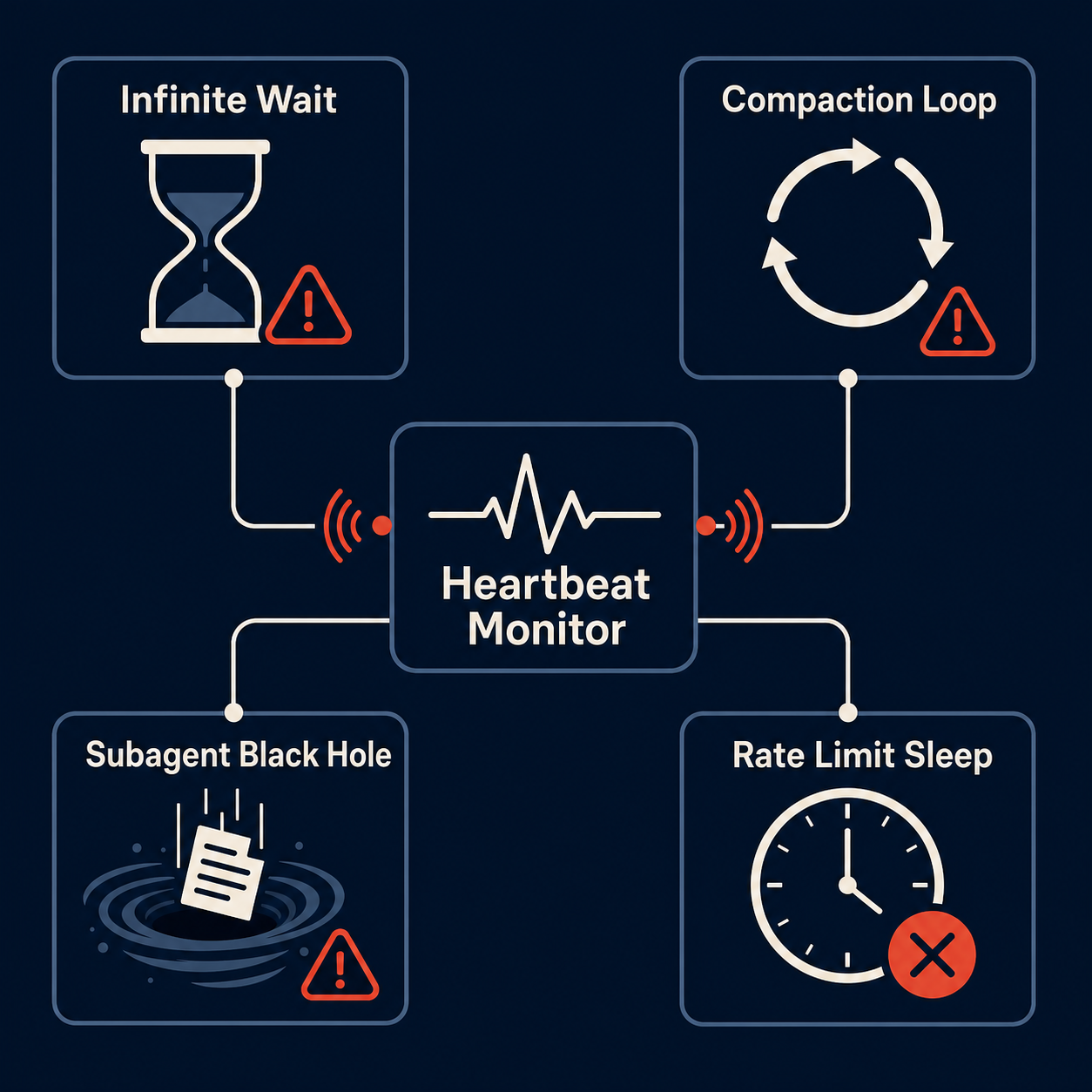
Bob Renze, running an autonomous task system, described these as “zombie tasks” — “alive by every metric except the one that matters.” He identified four stall patterns that recur across production deployments:
The Infinite Wait. A tool call hangs waiting for a response. No network timeout was configured. The agent keeps waiting because no error occurred to trigger recovery. The process is alive. Nothing is happening.
The Compaction Loop. The context window fills. The system tries to compact. Something goes wrong in the compaction logic. The task enters a loop, consuming tokens, neither completing nor failing.
The Subagent Black Hole. You spawn a subagent for parallel work. It fails silently in its isolated session. The parent task waits forever for a completion signal that never arrives.
The Rate Limit Sleep. You hit an API rate limit. Backoff logic says “wait 5 minutes.” The wait extends indefinitely. The task never wakes up.
These aren’t edge cases. They’re the default failure mode of any long-running agent system. The fix isn’t a better framework — it’s architecture that assumes the framework will fail.
Nathaniel Hamlett runs 23 autonomous cron jobs that discover, research, and submit to opportunities without human intervention. His approach, documented on earezki.com, externalizes all state. Every new cron invocation is a cold process with zero memory — coordination lives in the database, not the process. SQLite with journal_mode=WAL and busy_timeout serves as the coordination layer. PID lock files in /tmp prevent race conditions. Item-level commits prevent total data loss from a single API failure.
Here’s the coordination primitive:
| |
Three things matter here. First, BEGIN IMMEDIATE — without it, SQLite defers locking and you get SQLITE_BUSY under concurrency. Second, the heartbeat_at column: every task writes a timestamp on progress. A watchdog process checks updated_at, not PID existence. No heartbeat update in 10 minutes means the task is a zombie, regardless of what the process table says. Third, item-level commits: fail mid-batch, you lose one item, not the whole batch.
This externalized state model is the difference between losing hours of work and losing a single API call.
Here’s the watchdog that makes zombie detection automatic:
| |
The idempotency constraint is what makes kill-and-retry safe. If running a task twice corrupts state, you can’t kill zombies — you can only stare at them. Every operation in the pipeline must survive being run more than once. This means output filenames are deterministic, database inserts use INSERT OR REPLACE, and side effects are structured to be repeatable.
After implementing these patterns, Renze reported: 12 stalled tasks detected, all within 15 minutes. Silent failures dropped from 2–3 per week to zero. Average task completion fell from 8+ minutes to 4.2 minutes. Three false-positive timeout kills in week one, fixed by tuning thresholds.
The Orchestration Tax
Here’s a number that should bother you: some agent frameworks spend more tokens on orchestration than on the actual work.
When you put an LLM in the routing loop — “analyze the task, determine which agent should handle it, dispatch accordingly” — you’re paying for a model to make a decision that code could make deterministically. Every. Single. Invocation. The LLM reads the task description, reads the available agents, decides which to invoke, and fires. That’s 200–500 tokens before any real work begins.
Now scale that across 23 cron jobs running daily. That’s thousands of routing decisions per month, each one burning tokens and introducing nondeterminism. The LLM might route differently on Tuesday than it did on Monday. The same task, same context, different model response. Reproducible bugs become a fantasy.
Microsoft Conductor, released May 2026 under MIT license, takes the opposite approach. Workflows are YAML files. Routing between agents uses Jinja2 template matching — zero tokens, deterministic results. The LLM lives inside the task, not above it.
Here’s a Conductor-style workflow definition:
| |
Three things stand out in this workflow. First, the filter step is a shell script — no tokens consumed. Second, context mode is explicit per step: last_only for discovery (only the current prompt), explicit for research (only named input files), accumulate for writing (everything prior). Third, human_review is a built-in gate, not a bolted-on webhook — the workflow pauses and waits.
The economics are straightforward. A framework that routes via LLM might spend 300 tokens per routing decision. At $3 per million input tokens (GPT-4o pricing), that’s $0.0009 per decision. Tiny. Until you run 1,000 decisions a day, at which point it’s $0.90/day in routing overhead — roughly $27/month spent on nothing but deciding what to do next. That’s before the actual work.
Conductor’s orchestration layer costs $0. The difference isn’t the money. It’s the determinism. A YAML workflow produces the same routing decisions every time. An LLM router produces decisions that drift.
Context Engineering: The 5-Minute vs 3-Day Gap
A 5-minute task can hold everything in context. The system prompt, the instructions, the tool outputs, the intermediate results — it all fits. The agent stays coherent from start to finish.
A 3-day task cannot. The context window is a fixed-size resource, and as MindStudio’s analysis of agent failure patterns documented, LLM attention mechanisms treat recent tokens as more relevant than older ones. The system prompt and early instructions lose influence even while technically still present. The agent doesn’t “forget” — it just weights recency higher, and over hours of execution, that weighting becomes indistinguishable from memory loss.
This is context degradation. It’s one of six failure modes MindStudio identified in production agents, alongside specification drift (reinterpreting instructions over time), sycophantic confirmation (RLHF bias toward agreeableness), tool call failures, cascading failure, and silent failure. The operational patterns from the previous section — heartbeats, timeouts, externalized state — don’t fix these. They contain them. They turn undetected reasoning failures into bounded, observable events.
What fixes context degradation is context engineering. The emerging discipline, named by ByteByteGo as a 2026 trend, means controlling what information reaches an agent at each step. The agent doesn’t browse. It doesn’t explore. It gets exactly what it needs.
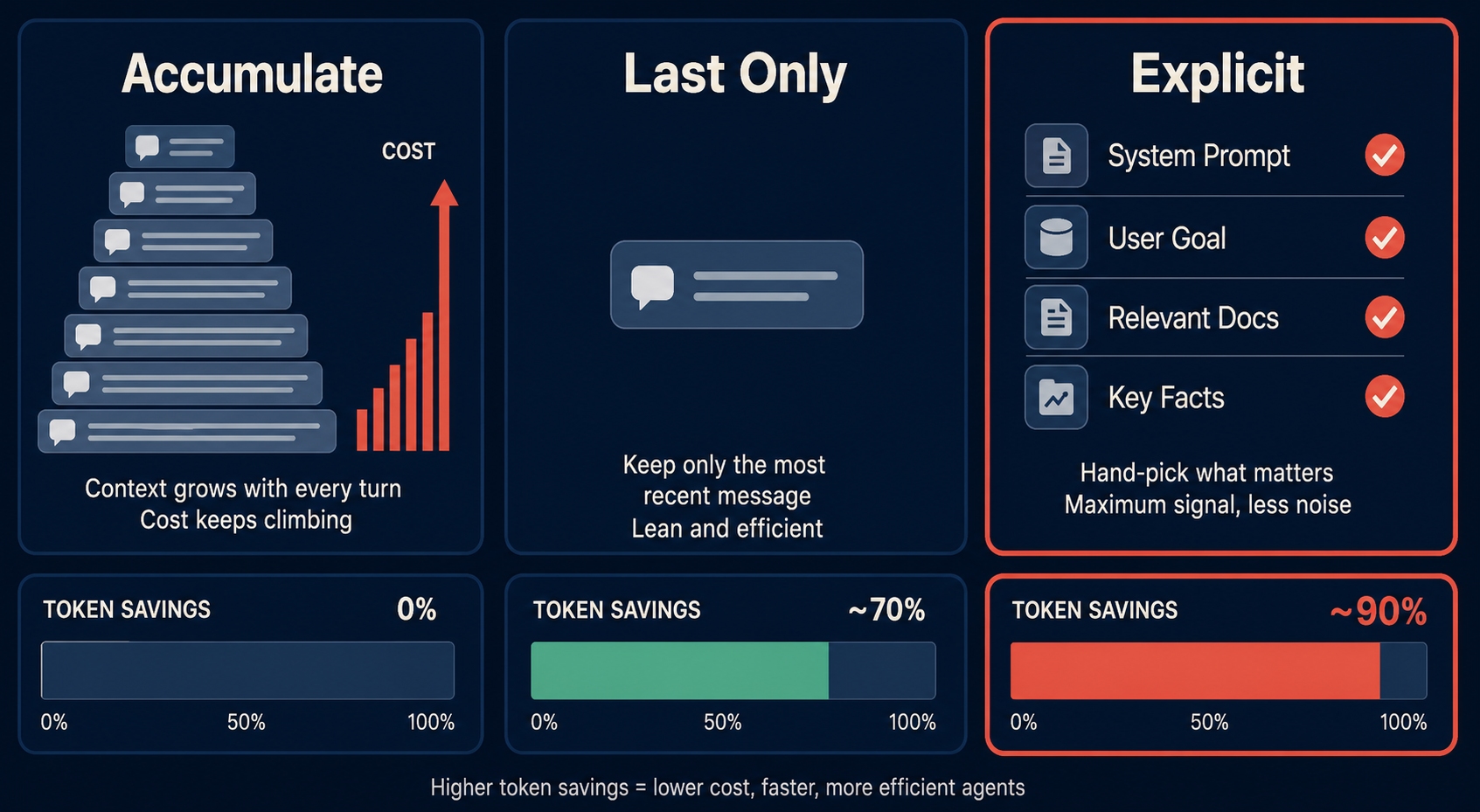
Microsoft Conductor formalizes this with three context modes:
Accumulate — the agent sees all prior step outputs. Use this for planning, analysis, and synthesis tasks where full history matters. It’s the most expensive mode but correct for jobs that need global context.
Last only — the agent sees only the output of the immediately preceding step. Use this for implementation, transformation, and formatting tasks. The agent has no business knowing what happened four steps ago. It just needs the current input.
Explicit — the agent sees only named dependencies listed in the workflow definition. Use this for review, testing, and validation. The agent gets exactly the files and outputs you specify, nothing else.
This isn’t a minor optimization. Running last_only instead of accumulate on a 10-step pipeline cuts the effective context window per step by roughly 90%. For a task that normally pushes against a 200K token context window, that’s the difference between fitting and truncating. And truncation is where context degradation begins.
The context manifest is the implementation. Each agent step receives a structured list: specific files, specific documentation sections, specific prior outputs. The agent doesn’t get to “look around” the codebase. Free-roaming access causes agents to make connections between unrelated files, draw false inferences, and drift from the original specification. Anthropic’s engineering team confirmed this pattern in their November 2025 post on long-running agent harnesses: agents working across multiple context windows with no memory between sessions need structured handoffs — an initializer agent that sets up the environment, structured feature lists, git commits as checkpoints.
Context manifests are the handoff mechanism. When agent A finishes and hands to agent B, B doesn’t inherit A’s entire conversation. It inherits a manifest: “here are the three files you need, here’s the output from step 4, here are the constraints.” Everything else is excluded.
What I Actually Run
After absorbing production failures, framework documentation, and the patterns that work for people running agents 24/7, the stack isn’t a single framework. It’s a composition.
Deterministic routing. YAML-defined workflows with Jinja2 routing. No LLM in the orchestration path. The router is code, not a model. Every invocation produces the same routing decisions. This alone eliminated a class of nondeterministic stalls that took weeks to debug under LLM-based routing.
Per-task LLM selection. Different tasks need different models. Classification and filtering run on smaller, cheaper models (Claude Haiku, GPT-4o-mini). Research and writing use frontier models (Claude Sonnet 4, GPT-4o). The workflow definition specifies which model each step uses. Mixing providers within a single pipeline is not a luxury — it’s cost control.
SQLite WAL for external coordination. Every task is a cold start. No in-memory state survives between invocations. SQLite with WAL mode is the coordination layer — task queues, heartbeats, lock files, item-level commits. It’s boring technology, which is the point. It doesn’t break in interesting ways at 3AM.
Heartbeat-based monitoring. A separate watchdog process checks heartbeat_at timestamps. Not PID existence. Not process status. An agent that’s alive by every OS metric but hasn’t written a heartbeat in 10 minutes is dead. The watchdog kills it, resets the task to pending, and the next cron cycle picks it up.
Idempotent kill-and-retry. Every operation must survive running twice. Deterministic output filenames, INSERT OR REPLACE, structured side effects. If the watchdog kills a task mid-execution, the retry doesn’t corrupt state. This constraint forces clean design — and clean design is what keeps pipelines running unattended for weeks.
Is this more work than installing LangGraph and wiring up a graph? Yes. Does it eliminate the 3AM debugging sessions where your agents have been running in circles for four hours while every dashboard shows green? Also yes.
Actionable Takeaways
Pick your orchestration model before you pick a framework. Graph-based (LangGraph), role-based (CrewAI), handoff-based (OpenAI/Claude SDK), or deterministic (Conductor). The model determines your failure modes more than the framework name does.
Externalize state. If your agent’s memory lives in process memory, a crash is total amnesia. SQLite with WAL mode, PID locks, and item-level commits — boring, reliable, survivable.
No LLM in the routing loop. The orchestrator should be code. The LLM goes inside tasks. This saves tokens and eliminates nondeterministic routing bugs.
Wall-clock timeouts on everything. Every task. Every subagent call. Every API request. Default to 60 seconds. Longer tasks opt in explicitly. Bob Renze’s checklist is right: if you can’t guarantee task completion or failure within a bounded time, you can’t participate in any time-sensitive coordination.
Heartbeat, not process check. A running process means nothing. A recent heartbeat means everything. The watchdog checks timestamps, not PIDs.
Context engineering is not optional. Free-roaming codebase access breaks long-running agents. Context manifests — explicit per-step file lists — keep agents focused. Accumulate mode for synthesis, last_only for implementation, explicit for validation.
Idempotency is the price of kill-and-retry. If you can’t safely kill a task mid-execution, you can’t recover from stalls. Make every operation safe to run twice.
The framework comparison charts aren’t wrong. LangGraph gives you state machines. CrewAI gives you role-based collaboration. Claude Code’s SDK gives you Anthropic-native tool use. But the chart doesn’t tell you that the real work isn’t picking the framework — it’s building the infrastructure that catches the framework when it stalls at 3AM and nobody’s awake to notice. That infrastructure is external state, deterministic routing, wall-clock timeouts, heartbeat monitoring, and context manifests. Everything else is demo-grade.